











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1. Introduction
Flood frequency analysis (FFA) is the basis for planning and designing bridges, culverts and flood control structures (Chow et al., 1998). The maximum capacity of these structures is defined by the design flow, which is the annual peak flow (APF) with a certain probability of being exceeded at least once during operation. This probability is known as risk and is usually expressed as a return period. Furthermore, this probability is selected by considering the economic, social and environmental effects that would be produced by the failure of the structure. Therefore, precise design flow estimates are important when evaluating the feasibility of a structure. However, due to stream flow variability, the precision of the estimates is drastically reduced when small samples are used in a conventional FFA.
Conventional estimates of the design flow are achieved via a frequency analysis of the APFs measured over a long period at a single gauging station. Assuming that the APFs are independent and identically distributed (IID), a relation between their magnitudes and non-exceedance probabilities can be achieved by fitting a cumulative probability function (CPF).
A regional flood frequency analysis (RFFA) is a well-known option for reducing the uncertainty in quantile estimates when sufficient and homogeneous data are available. A RFFA requires all available information from neighboring sites to obtain at-site estimates for a specific return period. Several previous papers have described the advantages of RFFA methods. Darlymple (1960) first introduced the index flood method. Chander et al. (1978) suggested a regional box-cox transformation. Wallis (1980) proposed the use of regional probability weighted moments. Boes et al. (1989) considered the Weibull distribution as a regional distribution. Moreover, Hosking and Wallis (1993) introduced select discordancy, heterogeneity and fitting measures. Cunnane (1998) suggested using the station-year method, whereas Sveinsson et al. (2001) proposed the population index flood method. The method introduced by Hosking and Wallis (1993) appears to display more acceptability in RFFA; its application can be found in Lim (2007), Saf (2009), Notto and Loggia (2009), Hussain (2011), and Rostami (2013).
Other options to reduce the uncertainty in estimating quantiles are "transfer methods". Zaidman et al. (2003) suggested two methods to transfer information from a donor basin to an object basin. In the first method, the standardized shape of the donor CPF is transferred. In the second method, the plotting positions of the events, occurring over the same period of time (year), are transferred. Dong et al. (2013) introduced a non-parametrical transfer method that uses an iterative procedure to gradually approximate the optimal CPF.
This paper proposes a new approach to reduce the uncertainty in the estimation of APF quantiles resulting from small sample sizes, and to dispense with neighboring information. This approach consists of simulating multiple APF samples to achieve a more accurate frequency distribution. To improve the accuracy, these synthetic samples must be conditionally simulated from a steadier variable. In this paper, APF samples are conditionally simulated using the annual mean flows (AMFs).
Hydrometric information from 13 gauging stations located in the Susquehanna River basin was employed in this study. APF quantiles were estimated according to the following methods: (1) a conventional FFA method, (2) a station-year method, and (3) the proposed method. The uncertainty of each method was measured by computing the coefficients of variation (CV) between the quantiles estimated from 10-, 20-, 30-, 40- and 50-year subsamples with those obtained from historical information.
2. Materials and methods
2.1 Study region
The Susquehanna River is located in the northeastern United States. With a length of 715 km, the Susquehanna is one of the longest rivers along the east coast. It has a normal flow of approximately 15 926 million m3/yr (monitored at Havre de Grace in Maryland) (SRBC, 2015).
The Susquehanna River basin has an area of 71 244 km2 and is divided into six major sub-basins: lower Susquehanna, middle Susquehanna, upper Susquehanna, Juniata, west branch Susquehanna, and Chemung. This basin belongs to the hydrological region II or Middle Atlantic and is one of the most flood-prone areas in the United States (SRBC, 2015).
2.2 Data
The stream flow time series used in this study were obtained from the National Water Information System of the United States (NWIS, 2015); 13 gauging stations in the Susquehanna River basin were selected. The locations of the study sites are shown in Figure 1.

To evaluate the independence of the series, the autocorrelation functions (ACFs) were contrasted with the limits proposed by Anderson (1942). To identify possible non- homogeneities, such as change points or trends in the time series, the Pettitt (1979) and Mann-Kendall tests (Kendall, 1938; Mann, 1945) were performed. A brief description of the series and the results are summarized in Table I.

2.3 Conventional FFA method
Let X represent the APFs and X = {x1,...,xn} be a sample of X at any site in the study region. Then, a conventional FFA method for APF quantile estimation can be defined as follows:
Step 1: Sort in ascending order
Step 2: Obtain the empirical non-exceedance probability of each x (1) in X, i.e., Pr[X≤ x (n)], using the Weibull's plotting position formula:
Step 3: Estimate a theoretical CPF of X, i.e., Pr[X ≤ x] (from Table II), by minimizing the sum square error (SSE) of the sample quantiles:

where
Step 4: Select (as the best CPF of X) the CPF with the smallest standard error of fit (SEF) (Kite, 1988) using the following relationship:
where k is the number of distribution parameters.
Step 5: Estimate the quantiles of X as
2.4. Station-year method
Let X represent the APFs and
Step 1: Standardize each
X
j
in the homogeneous region, i.e.,
Step 2: Join all Y j at the homogeneous region in one station-year series Y = {Y1 | ... | Y m } .
Step 3: Apply the conventional FFA to series Y; find the best CPF of Y, i.e., F(y; θ).
Step 4: Estimate the quantiles of Y as
Step 5: Estimate the quantiles of X as
2.5. Proposed method
Let Y represent the AMFs, Y = {y1,..., yn} be a sample of Y at any site in the study region, X represent the APFs and X = {x 1,..., x n} be a sample of X at the same site over a consistent recording period. The proposed method for APF quantile estimation utilizes the following steps:
Step 1: Sort Y in ascending order, i.e.,
Step 2: Obtain the APF ratios Θ {θ
1,..., θ
n} by dividing each x
t by its corresponding y
(i), i.e.
Step 3: Apply the conventional FFA to Y to determine the best CPF of Y, i.e., F(y; θ).
Step 4: Generate 100 000 random synthetic AMF defined as
Step 5: For each generated y(u), find its closest y (i) in Y and its corresponding θ i in Θ. Then using a window of size h = [n 2/3] centered on y (i), define Φ={ϕ 1 ,... ϕ m} as a subsample of Θ , where ϕ 1= θ max(1,i+h) and ϕ m= θ max(n,i+h) (Fig. 2). The specific window size was obtained after a trial and error process. It was observed that a window of this width provides a reasonable balance between flexibility and precision of the results.

Step 6: Assume that every ϕ j in Φ are equally likely to occur, i.e., Pr[ϕ = ϕ j]=1/m, and extract (from each Φ) a ϕ value, such that ϕ(ʋ)=sup{ϕ j ∈ Φ; ʋ ≤ j/m) by sampling v from a continuous uniform distribution, i.e., ʋ~U[0,1].
Step 7: Multiply each generated y(u) by the extracted ϕ(ʋ), i.e., x(y) = x(u) ∙ ϕ(ʋ).
Step 8: Estimate the quantiles of X as the q-th percentiles of the generated x(y).
3. Reliability of the methods
To evaluate the uncertainty in the estimated quantiles determined using the former methods, historical quantiles were first estimated from historical information. Then, different scenarios of available information were simulated by extracting 10-, 20-, 30-, 40- and 50-yr subsamples, and new quantiles were estimated. Finally, the coefficient of variation of the quantiles estimated from the 10-, 20-, 30-, 40- and 50-yr subsamples were computed using the following expression:
where
3.1. Reliability of the conventional FFA method
Let X represent the APFs and
Step 1: Apply the conventional FFA method to each X j for all 13 study sites to estimate the historical quantiles xj (q) for different non-exceedance probabilities q.
Step 2: From each X
j
extract i=1,...,nj
- m + 1 subsamples with size m equal to 10, 20, 30, 40 and 50 years for each site, i.e.,
Step 3: Apply the conventional FFA method to each
Step 4: Compute the CV of each (q) for all nj - m + 1 subsamples with respect to each xj (q) for all 13 study sites, using Eq. (4).
3.2. Reliability of the station-year method
Let X represent the APFs and
Step 1: Apply the conventional FFA method to each X j , for all 13 study sites to estimate the historical quantiles xj (q) for different non-exceedance probabilities q.
Step 2: From each X
j
extract i = 1,...,nj
- m + 1 subsamples with size m equal to 10, 20, 30, 40 and 50 years for each site, i.e.,
Step 3: Randomly select 500 combinations of three subsamples
Step 4: Apply the station-year method on each combination (in Step 3) to estimate the quantiles
Step 5: Compute the CV of each
3.3. Reliability of the proposed method
Let X represent the APFs and
Step 1: Apply the conventional FFA method to each Xj for all 13 study sites to estimate the historical quantiles xj (q) for different non-exceedance probabilities.
Step 2: From each Xj
extract i = 1,...,nj
- m + 1 subsamples with size m equal to 10, 20, 30, 40 and 50 years for all sites, i.e.,
Step 3: Apply the proposed method to each for all nj
- m + 1subsamples from the 13 study sites to estimate the quantiles
Step 4: Compute the CV of each
4. Results and discussion
The CV values for each subsample size (10, 20, 30, 40 and 50 years) by applying (1) the conventional FFA method, (2) the station-year method and (3) the proposed method were computed and contrasted.
Concerning all 13 study sites, approximately 200 CV values were computed for different q-th quantiles from each subsample size. Therefore, nearly 1000 CV values for each return period were computed for each method.
The variations in the set of estimated quantiles for the shortest length of records (i.e., 10 years) are shown in Figures 3-7. In these figures, the 50th per-centile is the median of the estimates, and the 10th and 90th percentiles are considered as lower and upper bounds, respectively. These figures show that the proposed method generates the narrowest limits compared with those obtained using the conventional FFA approach.

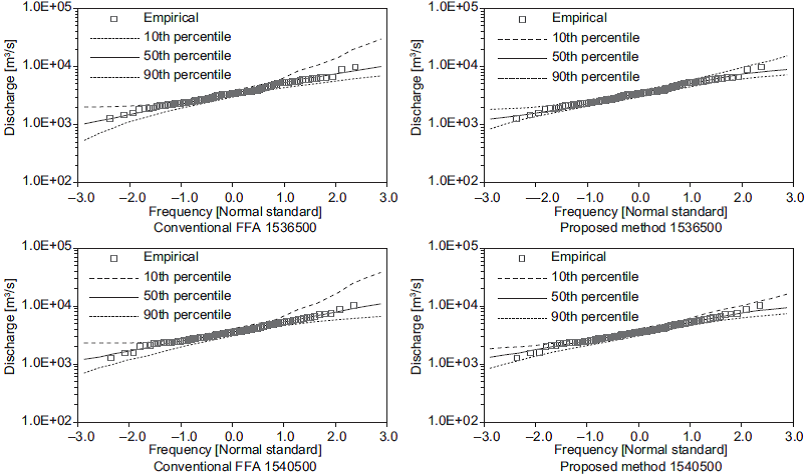
Fig. 4 (Continued) Quantiles obtained from 10-yr subsamples at stations 1503400, 1536500 and 1540500.
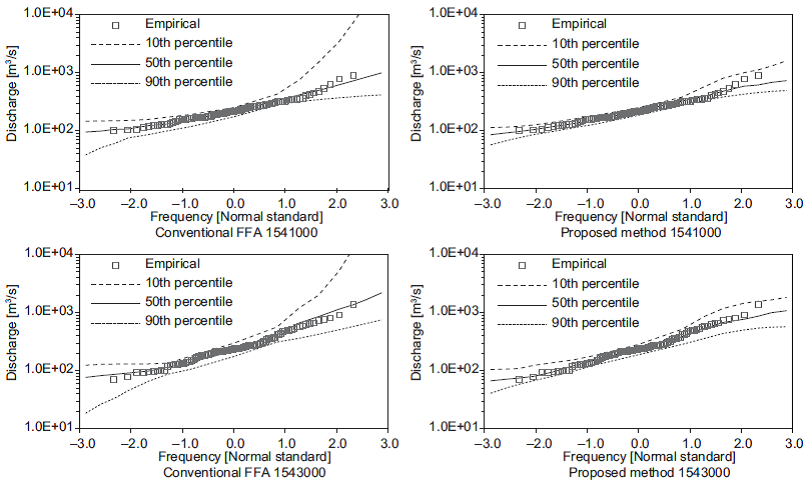
Fig. 5 Quantiles obtained from 10-yr subsamples at stations 1541000, 1543000 and 1545500. (Continue)
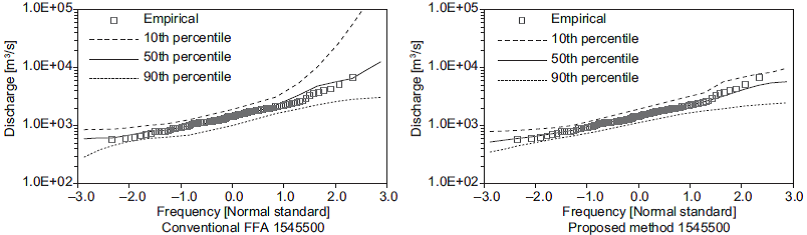
Fig. 5.(Continued) Quantiles obtained from 10-yr subsamples at stations 1541000, 1543000 and 1545500.


In general, lower CV values were obtained in 71% of the cases using the proposed method instead of the conventional FFA method. Lower CV values were obtained for a return of approximately two years in 33% of the cases, whereas 99% of the cases showed lower CV values for return periods exceeding 100 years.
Furthermore, in 67% of the cases, lower CV values were obtained using the proposed method instead of the station-year method. In 50% of the cases, lower CV values were obtained for a return period of approximately two years, whereas lower CV values were found for return periods exceeding 100 years in 93% of the cases.
The geometric means of all CV values for the same return period obtained from (1) the conventional FFA, (2) the station-year method and (3) the proposed method are contrasted in Figures 8-12.





5. Conclusions
A new approach for estimating APFs for different return periods is presented in this study. This approach consists of a conditional simulation process of synthetic samples of APFs and AMFs to achieve the frequency distribution. Thirteen gauging stations located in the Susquehanna River basin, which is along the east coast of the United States, were used in this study.
To evaluate the proposed method, the uncertainties in the quantiles estimated using (1) a conventional FFA, (2) a station-year method and (3) the newly proposed method were compared by computing.
The results indicated that the quantiles estimated using the proposed method varied less than those estimated via the conventional FFA, especially when they were estimated from 10-yr subsamples and for return periods exceeding 100 years. Therefore, the proposed method can reasonably reduce the uncertainty in quantile estimation from small sample sizes.
The results also showed that the quantiles estimated using the proposed method are equal or less than those computed by the station-year method, even if only a third of the information is used.
The analysis also demonstrated that the proposed method performed adequately when quantiles were estimated from the gathered samples. Moreover, more flexible frequency distributions were simulated using the proposed method than with the conventional frequency distributions.

