











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1. Introduction
According to data from the Executive Secretariat of the National Public Security System in Mexico (Secretariado Ejecutivo del Sistema Nacional de Seguridad Pública, SESNSP), from 2015 to 2019, each year was marked as the most violent in Mexico’s recent history. Throughout this period, 119 887 intentional homicides and 3 594 femicides were committed. These numbers equate to an average of 66 intentional homicides and two femicides per day during these five years. The data on homicide rates in Mexico, as reported by the World Bank, highlights that the country has alarmingly high levels of homicides compared to other countries. Specifically, in 2018, Mexico had a rate of 29 homicides per 100 000 inhabitants, which is higher than countries such as the United States, Japan, Spain, the United Kingdom, Sweden, Switzerland, Ireland, and Turkey, which do not exceed five homicides per 100 000 inhabitants. Furthermore, in comparison to other Latin American countries, Mexico has similar levels to Brazil (27) and Colombia (25) and is significantly higher than the levels of Argentina (5), Chile (4), Ecuador (6), and Peru (8). This information emphasizes the need for effective measures to address the high levels of violence in Mexico, especially when compared to other countries (World Bank, 2021).1
Furthermore, femicide stands out as a distinct component of crime in Mexico compared to other countries. Data from the World Bank reveals that the homicide rate for women in Mexico is 5.8 per 100 000 inhabitants, significantly higher than rates in developed countries such as the United States (2.2), Germany (0.9), France (0.7), Spain (0.5), Sweden (0.7), and Switzerland (0.7), among others. This data highlights the prevalence of violence against women in Mexico and emphasizes the urgent need for targeted interventions to address this specific form of violence.2 Compared to other Latin American countries, Mexico exhibits comparable levels of female homicide to countries like Colombia (4.2) and Brazil (4.3). Additionally, studies indicate a close association between femicide and gender violence, sexual harassment, sexual abuse, rape, organized crime, and human and drug trafficking. Prieto-Carrón et al. (2007) provide evidence that neighborhoods with high occurrences of organized crime, drug trafficking, and homicides are linked to a greater likelihood of femicide.
This research seeks to address crime in Mexico by providing an evidence-based analysis using a complexity model to characterize criminal behavior. This model identifies critical areas that significantly impact the criminal network by examining the evolution of crimes and their interrelationships. The study employs this model to offer policy recommendations for crime prevention. It highlights the importance of addressing violence against women in criminal activity, as it notably impacts overall crime rates. With a focus on Mexico, this study aims to contribute to the existing literature on crime prevention by providing a comprehensive understanding of the underlying factors contributing to criminal activity.
Moreover, the literature has established that criminal activity adversely affects economic activity in Mexico. Research indicates that elevated crime levels can harm investment levels, economic growth, and the welfare of individuals and communities.
Previous literature has shown that criminal activity can adversely affect Foreign Direct Investment (FDI). A study conducted by Torres et al. (2018) found that homicides and thefts have a statistically significant negative impact on FDI in Mexico. The same pattern has been observed in other nations, as demonstrated by Brown and Hibbert (2017), who examined information from 62 countries from 1997 to 2012 and found that FDI is similarly affected by violent crimes. Additionally, studies have indicated that criminal activity can adversely affect labor and productivity. Cabral et al. (2016) found that criminal activities have a negative effect on Mexican labor productivity from 2006 to 2016, which corresponded to the period known as the “drugs war period”. Additionally, during the same timeframe, Benyishay and Pearlman (2013) identified a 1% to 2% decrease in hours worked. Benyishay and Pearlman (2014) also discovered that higher theft rates decrease the probability that micro-enterprises in Mexico will expand their operations, resulting in a decline in economic activity. Conversely, Pan et al. (2012) found that the crime rate of neighboring states had a negative correlation with economic growth. Finally, González (2016) established a negative correlation between economic growth and crime rates in Mexico.
From an alternative perspective, criminal activity has significant direct economic costs. One way to evaluate these costs is through the accountability method, which divides all crime-related expenditures into three categories: social costs, private sector costs, and government costs. Social costs cover a range of expenses, such as lost income and victim expenses. Private sector costs include expenses incurred by households and businesses for crime prevention. Government costs comprise costs related to the justice system, police, and correctional facilities.
Using the aforementioned methodology, recent studies have measured the direct cost of crime as a percentage of Gross Domestic Product (GDP) for several countries. Chalfin (2015) estimates that the cost of crime in the United States is approximately 2.5% of the GDP. Olavarria-Gambi (2007) estimates that Chile’s total crime cost is approximately 6% of the GDP. The Inter-American Development Bank (IADB) estimates that for 17 Latin American countries, the average cost of crime is approximately 3.5% of the GDP, with an estimated 1.92% for Mexico (Jaitman et al., 2017).
From another perspective, the economic aspects of criminal behavior have been the subject of extensive study. Becker (1968) established the economic incentives for individuals to engage in criminal activities. Becker characterizes criminal behavior as a choice between productive and criminal activities concerning the available labor opportunities and highlights how this choice is closely related to labor market policies, the effectiveness and quality of the judicial system, and other economic factors. Recent literature has expanded on the determinants of criminal behavior, including wage and income inequality, poverty, cultural and family background, social exclusion, education, and other economic and social factors. A comprehensive review of 20 years of literature on crime from an economic perspective by Buonanno (2003) concluded that criminal activity is a complex phenomenon affected by various socioeconomic determinants. He highlights that understanding these determinants and their relationships is crucial for effective policy implementation.
The policy intervention methodology proposed in this study is based on the economic complexity approach. As outlined by Hausmann et al. (2013), the approach involves using a network procedure to examine the relationships between production outputs by region and to understand the evolution of production capabilities. The analysis examines each economic region and assumes that regions producing similar products have comparable production conditions. For instance, the analysis might indicate that the production of shirts is more closely connected to the production of pants than to the production of turbines. The intricacy of each product is established as a measure of the essential capabilities needed for its production. A product ordering by complexity is then created to implement policies. Similarly, this study uses a similar approach to construct a network of crimes and comprehend their progression. An ordering of criminal activities by their complexity is subsequently introduced to guide policy interventions. To summarize, this research aims to describe the crime network, the evolution of criminal activities (order), and identify crime characteristics for policy intervention using the economic complexity approach.
This study employed crime incidence data from state and federal jurisdictions at the state level from 2015 to 2019. The research outcomes reveal that the evolution of crime in Mexico commences with public transport robberies and ultimately leads to organized crime.
It represents a notable addition to the extant literature on economic complexity, crime behavior analysis, network analysis, public policy analysis, and machine learning applications. Additionally, it presents a fresh approach to analyzing criminal behavior with associated policy recommendations. Specifically, the findings indicate that preventative measures targeting femicide and rape would be the most productive means of dismantling the crime network. By targeting these crimes and the offenses linked in their network, it appears that overall crime rates can be reduced while also preventing the diversification of criminal activity.
The model used in this study can be considered an unsupervised model. It employs the data to estimate relationships between variables (crime incidence). Such a model is typically called a clustering model and is frequently classified as a type of machine learning model. The application of network analysis has become widespread across a variety of academic disciplines, including public policy, computer science, economics, and epidemiology. In the field of epidemiology, scholars such as Li et al. (2014), Aihara and Kim (2009), and Verdasca et al. (2005) have employed this approach to examine the spread and control of diseases. Within the computational field, network analysis has been used to identify potential nodes, as well as weak and strong links within networks, and to develop algorithms that efficiently dismantle them, Ren et al. (2018), Braunstein et al. (2016), and Han et al. (2021) are among the authors who have contributed to this area of research. Additionally, Kertész and Wachs (2020) argue that complexity analysis plays a crucial role in understanding criminal behavior, particularly in fraud and corruption. The authors suggest that the complexity approach has become an important tool for describing, analyzing, and detecting crime over the last three decades.
Various methodologies have been employed in crime behavior and network analysis, including social network analysis and spatial analysis. Several scholars have contributed to this literature, including Papachristos et al. (2013), Sierra-Arévalo and Papachristos (2015), Scott and Carrington (2011), and Neto (2017), among others. In Mexico, there has been a growing interest in investigating the correlation between complexity and crime. For example, Ríos (2017) quantifies the impact of crime on economic diversity through the lens of complexity.
2. Economic complexity methodology
The proposed model draws on the seminal works of Hidalgo and Hausmann (2009) and Hausmann et al. (2013), exploring the foundational concepts of economic complexity. Hausmann et al. (2013) develop a methodology to examine the progression of products across different economies, classifying them by complexity level based on the capabilities, resources, and environmental factors required for production. Complexity is defined as the magnitude of the material resources, productive capacities, and contextual elements, such as institutional framework and educational attainment, necessary for creating a product. These authors further demonstrate the construction of a product complexity index, providing a means of characterizing products in terms of complexity.
Building on the argument put forth by Hausmann et al. (2013), it can be argued that, similar to products, the commission of crimes demands specific capabilities. These include access to resources, educational level, institutional environment, and level of organization. This perspective suggests that crimes that require limited education, an ineffective institutional framework, and minimal organizational structures and resources are likely to be considered less complex, while those requiring greater levels of these capabilities may be viewed as more complex.
The algorithm is premised on the idea that certain geographical locations possess a predisposition for committing specific crimes, reflecting the area’s inherent capabilities. This predisposition can be formally defined as a competitive advantage for committing a crime in a particular location. By analyzing the crimes that have a competitive advantage in specific locations, it is feasible to comprehend their interplay with other crimes and develop a map of relationships, referred to as the proximity matrix. This matrix represents the conditional probability that two distinct crimes are committed in the same location and serves as the basis for constructing the product space, a two-dimensional visualization of the interactions between all crimes. The analysis of the complexity and the graph will serve as tools for comprehending the evolution of crime and formulating a strategy for its disruption.
In accordance with Mealy et al. (2017), in this study, complexity is established in a matrix format where the 𝑀° matrix represents crimes as columns and the 32 states in Mexico as rows. Each entry of the matrix depicts the average of every crime. To determine the competitive advantages, the matrix is transformed into a binary matrix with entries of 0 and 1, with 0 indicating that a state does not have a competitive advantage in committing a particular crime and 1 signifying the presence of such an advantage. This analysis aims to identify, for each state, those crimes more easily committed than the national average and to comprehend their relationships.
In further detail, let us define M 𝑒,𝑐 𝑜 as the element of the matrix 𝑀° for the state e and for the crime 𝑐. 𝑆 𝑒,𝑐 ( 𝑀 𝑒,?? 𝑜 ; 𝑀 𝑜 ) is defined as the ratio of 𝑀 𝑒,𝑐 𝑜 over the total crimes in state 𝑒 (sum of row 𝑒 in 𝑀°); and finally, 𝑆𝑐( 𝑀°) is defined as the crime ratio of crime 𝑐 (sum of column 𝑐) over the total sum of crimes (total sum of the matrix 𝑀°). Based on international trade theory, the revealed comparative advantage (RCA) function of the state e with respect to crime 𝑐 is defined as:
The function defines a specific crime as a competitive advantage for a given state when the proportion of that crime in the state is greater than the proportion of the same crime across the entire nation.3
An alternative approach for conducting the analysis is to use the singular value decomposition (SVD) of the RCA matrix. This method provides metrics related to the proximity matrix and complexity, as exemplified by Che (2020) in the context of policy recommendation. Nonetheless, recent research by Hidalgo (2021) has demonstrated that the economic complexity index already encompasses the information derived from the SVD descomposition. It is worth noting that the SVD can be interpreted as a Cobb-Douglas production function, indicating that both metrics essentially measure the production of goods or crimes.
The matrix 𝑀 is defined with the same size of 𝑀° with the results of applying the RCA function to the corresponding element in 𝑀°. Therefore, 𝑀 is the transformation of the matrix 𝑀° to 1 and 0 elements.
Following the above procedure, it is appropriate to introduce the concepts of diversity and ubiquity. Diversity is the collection of crimes that exhibit a competitive advantage in a given state, while ubiquity is the collection of states that engage in a particular crime with a competitive advantage. In a more formal sense, we define these concepts as follows:4
The concept of complexity can be expressed in terms of two matrix equations obtained
through the use of the operator 𝑑𝑖𝑎𝑔(.) that diagonalizes a vector. Let
In this formulation, the complexity of states and crimes is represented by vectors 𝑋 and 𝑌, respectively. Substituting the expression for 𝑋 from the first equation into the second equation yields:
The eigenvectors of the matrix
In this final step, the proximity matrix is constructed from the network under analysis. The proximity matrix captures the conditional probability of a particular crime occurring given the occurrence of another crime. Formally, the proximity matrix Ω can be defined as follows:
The network to be analyzed, known as the proximity matrix, is constructed as the minimum element-wise operator (min) among the matrices. The proximity matrix is a symmetric matrix that represents the proximity between crimes through nodes and links. Its symmetry implies that for two offenses 𝐴 and 𝐵, the conditional probability is 𝑃(𝐴|𝐵=𝑃(𝐵|𝐴), and therefore 𝑃(𝐴)=𝑃(𝐵).6 The variance in the matrix is given by the joint probability of two crimes, and since the matrix is not constant in all its elements (except the diagonal), it implies that the crimes are not independent of each other (𝑃(𝐴&𝐵)≠𝑃(𝐴)*𝑃(𝐵)). A joint density function is assumed for any pair of offenses 𝐴 and 𝐵 defined as 𝑓(𝐴,𝐵), which is increasing in both arguments. Hence, it is assumed that reducing the crime with the highest joint probability concerning the others would have a greater impact on the marginal probabilities. This argument is later resolved with the term centrality.
In other words, the proximity matrix measures the likelihood of producing different crimes and visualizes the potential pathways for diversifying criminal activities. Although it does not directly incorporate the concept of complexity, it will be highlighted later that this algorithm can also capture this aspect.
2.1 Decommissioning of the network
This section aims to explore the relationship between the centrality concept and proximity matrix in the context of policy intervention, which is one of the main objectives of this research.7
Reflecting on the network’s construction, the proximity matrix is established as the conditional probability of a crime being committed, given that another specific crime has occurred. As described in equation (4), it is the minimum element-wise of two matrices. Let us consider two crimes, denoted as 𝐴 and 𝐵, represented in two vectors within the matrix 𝑀. By applying the concept of ubiquity and equation (4), the conditional probability of crime 𝐵 occurring given the occurrence of crime 𝐴 can be calculated as:
The model construction implies that 𝑃(𝐵|𝐴)=𝑃(𝐴|𝐵) in the proximity matrix
due to the computation of the minimum of both probabilities, as described in
equation (4). This
characteristic also guarantees the symmetry of the matrix. The impact of
proximity matrix definition on complexity metrics has been briefly discussed by
Hausmann and Klinger (2007). To
verify the assumption that 𝑃(𝐵|𝐴)=𝑃(𝐴|𝐵), an analysis was conducted on the
matrices
The assumption that 𝑃(𝐵|𝐴)=𝑃(𝐴|𝐵) leads to the conclusion that 𝑃(𝐴)=𝑃(𝐵), indicating that all crimes have the same probability. As a result, the proximity matrix captures the joint probability among crimes, imposing a normalization in probability measures across crimes. It is important to note that the matrix is not constant, as observed in the data, which implies that 𝑃(𝐴∩𝐵)≠𝑃(𝐴)𝑃(𝐵).
The interdependence among crimes implies that preventing one crime could affect the probability of committing another crime. We define a set 𝑆 containing all possible events, and the events represented in the proximity matrix are a subset of 𝑆. It is worth noting that we define a probability space with a 𝜎-algebra, a subsample of events 𝑆 (discrete), and a probability function. The subset represents the events in which a crime has already occurred. Therefore, the marginal probability of event 𝐴 can be computed as:
Assuming that the function 𝑓 is strictly increasing in both arguments, it follows that an increase in the value of an element 𝑠∈𝑆 will result in an increase in the probability of event 𝐴.9 The objective is to identify the element 𝑠∈𝑆 that will minimize the probability of event 𝐴, representing the crime of interest. In other words, it aims to identify the element with the highest contribution to the probability of committing another crime. Preventing this particular event would lead to a greater reduction in the likelihood of the other crimes occurring.
We obtain the joint probabilities for all tuples of crimes (function 𝑓 for some 𝐴) from the proximity matrix. Under this assumption, given that one crime has been committed, we compute the sum for every row in the matrix (excluding the diagonal) and divide it by the total number of crimes (rows). This operation can be expressed mathematically as a matrix operation:
Where 1(??) is a vector of ones with the corresponding size, 𝐶 is a constant value (number of crimes) and Ω′ is equal to Ω but with the diagonal entries equal to 0. The entries of 𝑉 provide information about the average contribution of each crime to the probability of another crime being committed, given that a crime has already occurred. A higher value of the 𝑗-th entry in 𝑉 compared to the 𝑖-th entry indicates that the crime represented by the 𝑗-th row of the proximity matrix, on average, contributes more to an increase in the probability of committing another crime than the crime represented by the 𝑖-th row. As a result, preventing crime 𝑗 will have a greater impact on reducing the probability of crime production compared to preventing crime 𝑖. Hence, we identified the crime with the highest average contribution as a potential target for crime prevention. The proposed metric is akin to the closeness centrality measure in network analysis, where probabilities correspond to edges. In this context, closeness centrality can be computed as the sum of joint probabilities. Drawing on this analogy, our probability-based approach is connected to network analysis, enabling the use of existing tools for centrality computations.
The closeness centrality does not fully account for the fact that a node, such as a crime, can be connected to other nodes with high centrality. We can use eigenvector centrality to capture this aspect of the network structure better. This measure assigns a centrality score to each node based on its proximity to other nodes while considering the centrality of those neighboring nodes. As a result, the eigenvector centrality provides a more comprehensive view of the network structure. Therefore, it is a more suitable metric for identifying crimes likely to have the greatest impact on reducing criminal activity.
3. Data
The analysis in this study employed data on crime incidence between 2015 and 2019 from both state and federal jurisdictions in Mexico. The data was gathered on a state-wise basis from the SESNSP. The year 2020 was excluded from the analysis to exclude the effect of the COVID-19 pandemic on crime rates.
It is pertinent to note several significant features of the data. The analysis was performed using aggregated data at the state level, which enabled the collection of crime data for state and federal jurisdictions and ensured comparability across all states in Mexico. Currently, it is not feasible to construct detailed crime data at the municipal level for the entire country (federal crime data is only available at the state level). Consequently, this leads to a sparsity issue in the model. The model thus has a trade-off between incorporating fine-grained local characteristics in geographical terms and ensuring the completeness of the data.
It should be emphasized that extreme cases arise when the data is characterized at a very fine-grained level of analysis (e.g., neighborhoods), as the resulting matrix 𝑀 may have only one element equal to 1 for every row.10 In such cases, equation (3) does not have a solution. Conversely, there is no solution if only one aggregation unit is used. Therefore, it is essential to consider the aggregation of units (states/municipalities, etc.) or crimes (higher or lower aggregations) that ensure variance and capture some of the local features implicit in the relations between crimes. As a result, the analysis does not incorporate local crime conditions, such as street conditions or neighborhood income levels. The model focuses on state-level characteristics and makes inferences based on the relationships between crimes.
An alternative approach to address this issue is to construct units that ensure similar characteristics and have a suitable level of aggregation for the analysis. In the present study, the state-level aggregation was chosen due to the completeness and comparability of the crime data and to ensure some homogeneity in key factors such as income, poverty, state of law, and institutional context, among others. However, it is acknowledged that this approach may not capture more localized effects, such as the conditions of specific neighborhoods. Thus, future research could explore the development of new aggregation units that capture different characteristics of interest.
The complexity of the crime network was assessed using the average annual incidence of crime at the state level, considering both the type and subtype of crime defined by the classification methodology of the SESNSP. For the federal jurisdiction, only the concept of crime was considered based on the SESNSP classification catalog. A total of 9 907 975 crimes were classified into 59 different categories. To ensure the robustness of the analysis, certain categories of crimes were excluded from the analysis, namely: family violence, rapture for marital purposes, incest, failure to comply with family assistance obligations, and other crimes against the family, as they are known to be significantly underreported, which may skew the indicators. Moreover, the categories “Other crimes of the General Health Law (LGS)” and “Other crimes in Federal Laws and Codes” were also removed as they encompassed a broad range of crimes within a subset of classification.
Appendix A demonstrates that the inclusion or exclusion of underreported crimes in the analysis does not affect the model’s solution, assuming that all crimes have the same level of underreporting. However, we removed certain crimes from the analysis because we sought to maintain a similar level of underreporting across the sample. The crimes of family violence, rapture for marital purposes, incest, failure to comply with family assistance obligations, and other crimes against the family have an exceptionally high underreporting rate of 99%, as reported by México Evalúa. In addition, we present a model in in Appendix A that accounts for the impact of underreporting on the crime data. Despite this adjustment, the overall results remain consistent. The final sample comprises 87% of all reported crimes from 2015 to 2019, encompassing a total of 50 distinct crime categories.11
It is important to acknowledge that under-registration affects all crimes, which could impact the results’ validity. It is assumed that the SESNSP registry accurately reflects the percentage composition of crimes for each state and that the under-registration rate is roughly similar across all states. Thus, the relative measurement of one crime concerning another should not be biased. To verify the robustness of the findings, an analysis was conducted in Appendix B that considers the under-registration rate for each crime. However, the results of this analysis remained consistent with the general conclusions drawn in the absence of this consideration.
In constructing our dataset, we decided to exclude the modality of crimes as a classification variable. This decision is because the SESNSP catalog does not consistently characterize all crimes as violent or non-violent. This could lead to subjective criteria being used to determine how to split the crime data, which would complicate the construction of the dataset. Therefore, we chose to use the classification system already established by the Mexican government to maintain consistency and avoid any unnecessary subjective interpretations.
4. Results: crime complexity ordering
During the calculations above, the complexity of each crime is determined, culminating in the establishment of a ranking among all crimes. Additionally, the evolution of crimes is characterized based on their complexity. The model classifies crimes into two broad categories, which are referred to as high-complexity (positive complexity) and low-complexity (negative complexity).12 The low-complexity category encompasses most robberies, except for those targeting banking institutions or machinery. Conversely, the high-complexity crimes are primarily federal jurisdiction offenses, such as organized crime, crimes against public health, and “huachicoleo”, among others, and state jurisdiction offenses, such as homicide, femicide, and kidnapping.13
The unsupervised model identifies organized crime as the one with the highest complexity, while robbery in collective public transport is the lowest. Previous research by Mealy et al. (2017) suggest that the economic complexity index is comparable to spectral clustering, which is widely applied in image recognition, web page ranking, information retrieval, and RNA motif classification, among other fields. These machine learning algorithms are commonly used in Artificial Intelligence (AI) applications. Thus, the model can be viewed as a machine learning model that learns about criminal behavior and makes inferences regarding its evolution.
Upon analyzing the four crimes with the highest complexity -namely organized crime, accidental homicide, trafficking of minors, and intentional homicide- it was found that organized crime and trafficking of minors demand significant resources and organization, which can explain their high-complexity. Additionally, accidental homicide and intentional homicide were relatively classified together, despite intentional homicide being considered less complex than accidental homicide, which may seem counter intuitive. The categorization of crimes may offer a potential explanation for the relative complexity of intentional and accidental homicide.
The available evidence suggests the possibility of fraudulent registration of homicides as accidental deaths. Accidental homicides should exhibit a random pattern due to their unintentional nature. However, recent data from the SESNSP indicate an increasing trend in accidental homicides, as well as a positive correlation with intentional homicides. The data suggests that certain states may be manipulating data for various reasons. A comprehensive review of crime registration conducted by México Evalúa (2020) supports this claim and documents the evidence of such practices.
The above findings highlight a significant concern regarding the classification of accidental homicide, which appears to be influenced by intentional homicide. Moreover, intentional homicide is closely linked with various other criminal activities, including organized crime, kidnapping, and crimes against health, among others. Therefore, accidental homicide may be capturing this complexity, reflecting a significant component of intentional homicide.
Regarding the low-complexity crimes, it is found that robbery in collective public transport, theft of auto parts, robbery in individual transport, and forgery occupy the top positions. Their prevalence is likely the main determinant for their classification as low-complexity crimes. However, the data does not support this explanation, as these crimes only represent around 3% of all crimes. Moreover, the argument that prevalence alone determines high-complexity crimes does not hold either for the same reason.
The results obtained from the analysis provide insights into the progression of criminal activities in Mexico, indicating an incremental increase in criminal complexity that appears to correlate with the severity of the crime. Hausmann et al. (2013) mention that the complexity index represents an estimation of a region’s productive capacity. In the present case, this crime transition indicates unobserved capabilities. Further research could delve into the underlying factors that influence the complexity index, including but not limited to demography, economic conditions, law enforcement, and institutional environment. Table 1 displays the crimes ranked from high-complexity to low-complexity; the complexity transitions from positive to negative values, highlighting two complexity groups.
Table 1 Complexity and centrality by crime in Mexico
| Crime Type / Subtype | Complexity | Centrality |
| 1 Federal Law Against Organized Crime (L.F.C.D.O... | 1.282244 | 0.116838 |
| 2 Homicide / Accidental Homicide | 1.114279 | 0.169203 |
| 3 Trafficking of minors / Trafficking of minors | 1.109835 | 0.066315 |
| 4 Homicide / Intentional Homicide | 1.072569 | 0.1705 |
| 5 Robbery / Bank robbery | 0.967762 | 0.170021 |
| 6 Kidnapping / Kidnapping | 0.966362 | 0.162753 |
| 7 Other Crimes / Other Crimes | 0.960398 | 0.172158 |
| 8 Rape / Rape | 0.954729 | 0.178588 |
| 9 Femicide / Femicide | 0.873179 | 0.176932 |
| 10 Against Health / Against Health | 0.871286 | 0.165363 |
| 11 Drug dealing / Drug dealing | 0.724743 | 0.151585 |
| 12 Hindering prosecution or apprehension / Hinder... | 0.702957 | 0.164484 |
| 13 Human trafficking / Human trafficking | 0.591491 | 0.154977 |
| 14 Corruption of minors / Corruption of minors | 0.585163 | 0.165804 |
| 15 Abortion / Abortion | 0.544504 | 0.14767 |
| 16 Robbery / Motor vehicle theft | 0.542611 | 0.150154 |
| 17 Robbery / Robbery of machinery | 0.517433 | 0.153746 |
| 18 Dispossession / Dispossession | 0.495476 | 0.169062 |
| 19 Other crimes that violate sexual freedom and s... | 0.474758 | 0.15733 |
| 20 Falsehood / Falsehood | 0.421231 | 0.176206 |
| 21 Crimes committed by public servants / Crimes c... | 0.406796 | 0.150411 |
| 22 Other crimes that threaten life and physical i... | 0.340641 | 0.163397 |
| 23 Statutory rape / Statutory rape | 0.340377 | 0.161657 |
| 24 Sexual coercion / Sexual coercion | 0.274787 | 0.154193 |
| 25 Sexual abuse / Sexual abuse | 0.220053 | 0.17231 |
| 26 Breach of trust / Breach of trust | 0.219709 | 0.163593 |
| 27 Property damage / Property damage | 0.218341 | 0.156179 |
| 28 Robbery / Street robbery | 0.188597 | 0.141702 |
| 29 Robbery / Home Invasion Robbery | 0.045849 | 0.152078 |
| 30 Extortion / Extortion | 0.002726 | 0.143424 |
| 31 Injuries / Accidental Injuries | -0.004048 | 0.12629 |
| 32 Robbery / Robbery of delivery people | -0.054524 | 0.087013 |
| 33 Other crimes against property / Other crimes a... | -0.076549 | 0.139845 |
| 34 Sexual harassment / Sexual harassment | -0.126157 | 0.162789 |
| 35 Fraud / Fraud | -0.187616 | 0.162339 |
| 36 Threats / Threats | -0.188564 | 0.15276 |
| 37 Robbery / Other Robbery | -0.220298 | 0.139085 |
| 38 Other crimes of the State Jurisdiction / Other... | -0.227526 | 0.066913 |
| 39 Electoral / Electoral | -0.232462 | 0.13867 |
| 40 Injuries / malicious injuries | -0.309035 | 0.138732 |
| 41 Against the environment / Against the environment | -0.621757 | 0.100565 |
| 42 Gender violence in all its forms different fro... | -0.810025 | 0.040345 |
| 43 Robbery / Comercial robbery | -1.006022 | 0.112066 |
| 44 Robbery / Robbery in individual public transport | -1.146763 | 0.124403 |
| 45 Other crimes against society / Other crimes ag... | -1.157448 | 0.100623 |
| 46 Robbery / Robbery on public roads | -1.776704 | 0.081811 |
| 47 Robbery / Robbery of auto parts | -1.955656 | 0.071711 |
| 48 Robbery / Robbery in individual transport | -2.008686 | 0.053062 |
| 49 Counterfeiting / Forgery | -2.242112 | 0.063859 |
| 50 Robbery / Robbery in collective public transport | -3.678936 | 0.026626 |
Notes: The presentation of crime type and subtype is limited to those within the state jurisdiction. In the case of federal crimes, only the concept is presented. It is worth noting that the “Other Crimes” category includes federal crimes such as “huachicoleo” and others.
Source: Own elaboration.
The presented order depicts the evolution of crime, where theft is generally observed to be at a low level of complexity, except for theft of machinery and banks. Following are crimes that threaten the well-being and dignity of individuals, including gender violence, threats, injuries, harassment, and sexual abuse. The next group of crimes escalates to those that threaten freedom and life, such as human trafficking, kidnapping, crimes against health, femicide, and rape, leading to the highest levels of crime complexity, which culminate in the trafficking of minors and organized crime.
The arrangement of crimes in the proposed order reflects a progression in the capabilities required to commit them. While crimes such as theft are characterized by a relatively low level of specialization and resources, the robbery of a banking institution demands a higher degree of both. It is possible that the grouping of intentional and accidental homicide together is due to the similarity of the capabilities required to execute each crime, despite their different motives. Similarly, femicide is ranked closely in terms of complexity, indicating a similar level of capabilities required, even though the motivation behind the crime is distinct. These observations suggest that the proposed model offers a good fit for the data.
The findings depict a hierarchy of crime evolution that describes the escalation of crime in complexity. It is plausible that criminals acquire knowledge and resources to perpetrate more complex crimes, such as transitioning from robbing a collective to joining a criminal organization and subsequently engaging in sex-related offenses and murder. Alternatively, this hierarchy could also reflect the evolution of the institutional environment in a specific region, which may facilitate the production of crimes of a certain complexity. Such an environment could result from corruption at different levels of government. Consequently, states with favorable institutional conditions for certain types of crimes may develop different levels of criminal complexity.
Finally, this ordering of crime evolution represents a significant step toward developing more effective and efficient preventive policies. It provides a deeper understanding of the genesis of crime based on quantitative measures, facilitating the generation of targeted policies to prevent its escalation. This suggests that the most effective way to address crime in the future may be to intervene at the early stages of its complexity. Such preventive policies can take various forms, such as improved social services and education programs, community policing initiatives, targeted interventions to address specific risk factors associated with particular crimes, and broader measures to improve at-risk populations’ social and economic conditions.
4.1 Testing the crime evolution theory
A Vector Autoregression (VAR) model was employed to investigate the order of
crime evolution. The purpose of this model was to provide evidence supporting
the notion that the evolution of crime proceeds from lower to higher complexity.
The model was constructed using the vector
The clusters generated by the methodology were used to distinguish between high and low-complexity crimes, where positive values represent high-complexity crimes and negative values represent low-complexity crimes. Subsequently, the data was processed to create a panel with 384 observations covering quarterly data from 2017 to 2019, aggregated into two categories (high and low-complexity) of crime rates. The estimation was performed using 𝐾=2; the model included only two lags because higher orders of lagged variables were found to be insignificant. The Dickey-Fuller test confirmed the stationarity of the series. The estimated model is presented below:
The matrix Π capture the interaction between lagged and present values. Before differencing, the series were detrended using a linear and quadratic trend. A Vector Error Correction (VEC) model was also estimated to account for potential co-integration among the series.
The results of the estimation provide significant evidence regarding the evolution of crime. As expected, the analysis shows that, in general, increases in low-complexity crime rates have a positive impact on future high-complexity crime rates. Table 2 presents the results of the estimation.
Table 2 Estimation VAR model
| VAR | VEC | |||
| ∆Yi,1,t | ∆Yi,2,t | ∆Yi,1,t | ∆Yi,2,t | |
| ∆Yi,1,t−1 | *0.43 | -0.09 | *0.40 | -0.00 |
| ∆Yi,2,t−1 | *0.33 | *0.76 | *0.43 | *0.42 |
| ∆Yi,1,t−2 | -0.08 | 0.01 | -0.07 | 0.02 |
| ∆Yi,2,t−2 | -0.10 | *-0.18 | -0.15 | -0.00 |
| Error vector | Yes | Yes | ||
| Obs. | 384 | |||
Notes: *Significance at 90% with a bootstrap procedure. Source: Own elaboration.
Upon analyzing the VAR model, it was observed that the estimated effect of
These results provide evidence to support the proposed order of crime complexity. The estimations suggest that crime complexity progresses from low to high complexity. For instance, it is possible that by preventing low-complexity crimes today, such as robberies, we can prevent high-complexity crimes in the future, such as homicides. This is because the capabilities necessary to commit low-complexity crimes could be a precursor to committing high-complexity crimes. Thus, disrupting initial capabilities to commit low-complexity crimes may also prevent more severe crimes from occurring in the future.
4.2 Crime network
In some cases, it may not be feasible to solely address the early stages of crime evolution. Hence, understanding the relationships between different types of crimes can aid in determining the optimal crime to prevent. Such a crime would be related to many other types of crimes and may generate negative externalities. The proximity matrix can be used to identify the relationships between crimes. While every crime is related to all other crimes, not all relationships are equally strong. Figure 1 provides a visual representation of the relationships between 50 different crimes, where each node corresponds to a crime and each line represents a relationship. Only the strongest relationships are depicted, and the nodes are colored according to the harm done defined in the SESNSP catalog. Furthermore, black nodes indicate the grouping of crimes under federal jurisdiction. The proximity matrix can aid in identifying the best crime to prevent, considering its relationship with other types of crimes.
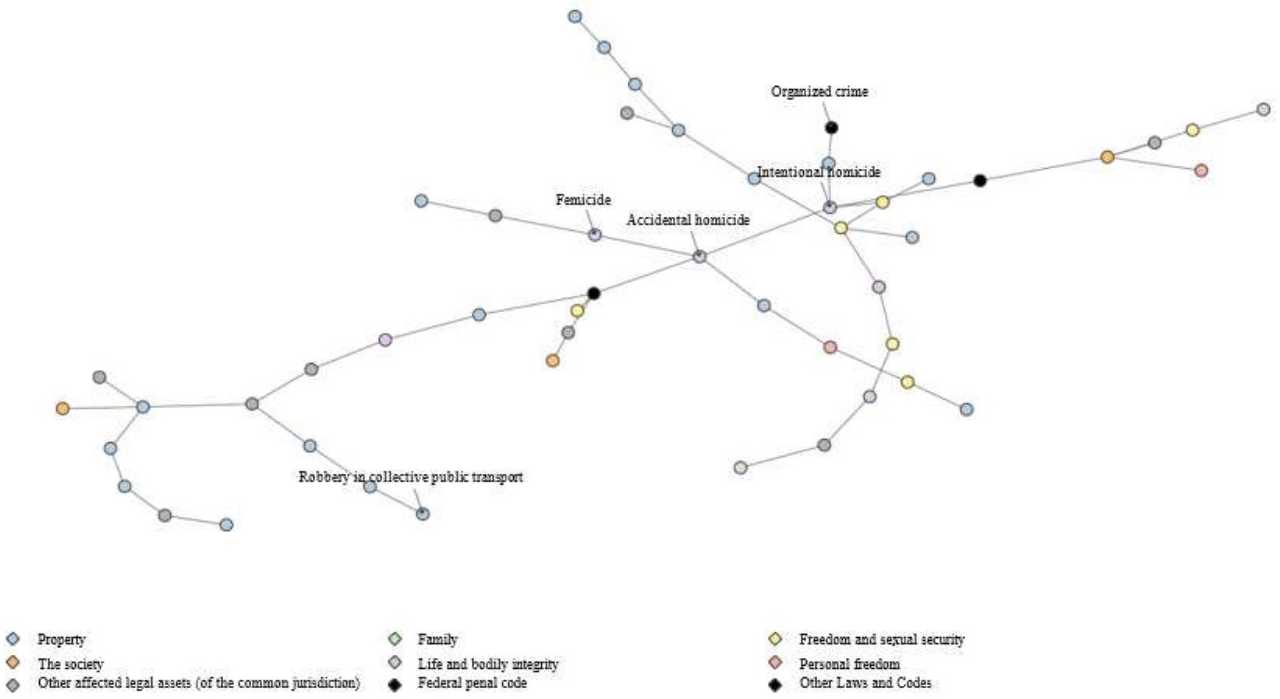
Notes: The color assigned to each node represents the category of goods affected by the crime, as defined by the SESNSP. Only the strongest connections between the nodes, determined using the Kruskal algorithm, are displayed. The Fruchterman-Reingold algorithm was used to position the nodes in the graph. It should be noted that the graph is a simplified representation of the proximity matrix. Source: Own elaboration.
Figure 1 Crime space
Figure 1 shows that different types of robberies and crimes, such as threats and fraud are grouped together (as represented by blue and gray nodes), suggesting that these crimes require similar capabilities to be committed. Notably, the blue node in the central area of the graph represents the crime of the least complexity (robbery in collective public transport), while the black node in the upper part of the graph represents the crime of the highest complexity (organized crime). Thus, figure 1 can also be interpreted as a path of complexity and diversification of crimes, highlighting the relationships between them. Furthermore, the graph serves as a two-dimensional evolution map of crimes that considers similar capabilities, not solely based on complexity.
In figure 1, accidental homicide, intentional homicide, and femicide are depicted as immediately connected, indicating that these three crimes share similarities in terms of the capabilities required to commit them (purple nodes at the center of the graph). It is important to emphasize that this clustering occurs despite the model’s lack of information regarding the fact that all three crimes ultimately result in loss of life. As a result, the joint probability of a homicide being committed is more closely related to femicide than to other crimes.
The preceding analysis reveals a significant finding regarding the escalation of gender-based violence. By examining the closest relationships or highest joint probabilities among crimes, it is observed that gender violence, represented by the green node at the bottom of figure 1, is immediately connected to malicious injuries, sexual harassment, and sexual abuse and finally culminates in rape. This pattern of escalation accurately reflects the behavior of sexual violence and is appropriately captured by the model. The result sheds light on the underlying dynamics of gender violence and provides valuable insights for policymakers and practitioners to develop effective prevention and intervention strategies.
Furthermore, the network analysis conducted in this study demonstrates that femicide and rape are the most central crimes in the crime network, as indicated by their high eigenvector centrality (as previously discussed in section 2). Specifically, these crimes exhibit the highest conditional probabilities with other crimes, implying that addressing them can generate positive externalities in preventing other related crimes. Table 1 provides a summary of the centrality metrics for each crime. Notably, in figure 1, these crimes are represented by the central purple nodes and their closest associated yellow node. It is worth noting that the centrality measure was computed using the proximity matrix that considers all interactions among crimes, as opposed to only the strongest ones depicted in figure 1. The use of the closeness centrality measure as an alternative method also resulted in femicide and rape being identified as the top two most central nodes, but not in the same order.
Thus, it is plausible to argue that preventing these two crimes could benefit public safety. Specifically, decreasing the incidence of either of these crimes will likely yield the greatest reduction in the marginal probabilities of other crime incidences.
To address the complexity inherent in the creation of a crime, a comprehensive preventive policy must consider various aspects of society, including economic and social environments, institutional development, and other factors. By doing so, such a policy could effectively reduce the capabilities required for the particular offense under consideration as well as those common to other offenses. Specifically, given the centrality of femicide and rape in the crime network, a desirable policy in this context should prioritize gender violence, with a particular focus on these two offenses. By incorporating these key elements and addressing the underlying complexity of crime, such a policy could have a significant impact on overall security.
On the other hand, proximity alone does not fully capture the complexity inherent in the evolution of crime. However, even when only considering the complexity, preventing gender violence remains an effective strategy since it can prevent the creation of more complex crimes, such as trafficking in minors, crimes against health, and kidnappings, among others. In other words, preventing femicide and rape has implications for crime prevention not only in the present but also in the future, as it may prevent the occurrence and diversification of more severe crimes. Therefore, implementing policies to prevent gender violence should be a priority in the fight against crime.
In this context, prevention efforts should begin with addressing gender violence, followed by sexual harassment, then rape, and finally, femicide. In this case, femicide and rape incorporate all of the capabilities of the preceding crimes. Consequently, if a criminal does not develop the capabilities incorporated in gender violence, the probability of committing more complex crimes, such as drug trafficking, is diminished. Alternatively, prevention of gender violence may also prevent childhood maltreatment, a risk factor for future violent crimes such as homicides, rape, and drug offenses.
The relationship between femicide and several crimes has been highlighted by the World Health Organization (WHO). For instance, WHO (2012) identifies femicide as being associated with verbal harassment, emotional abuse, physical or sexual abuse, and murder. Furthermore, WHO (2012) also identifies several risk factors that are associated with femicide, including unemployment, gun ownership, problematic alcohol and drug consumption, gender inequality, and low government social spending. These factors can all be considered as capabilities that enable the incidence of femicides.
In the context of violence prevention, the impact of violence against women extends beyond immediate harm to the individuals affected, as it can have lasting effects on future generations and society as a whole. According to Guedes and Mikton (2013), exposure to violence against women during childhood increases the risk of experiencing or perpetrating different forms of violence later in life. Additionally, such disclosure has been linked to child maltreatment and abuse. Moreover, a longitudinal study by Widom and Maxfield (2001) -on abused and neglected children during the 1970s- found that this violence increases the likelihood of future delinquency and criminality by 29%. These findings underscore the need for comprehensive prevention policies that prioritize reducing violence against women and its associated negative outcomes.
The evidence demonstrates that violence against women can be a central factor in current and future violence and crime. As a result, preventing femicides and violence against women can create a societal environment that discourages criminal behavior now. This approach creates conditions that decrease the likelihood of violent behavior in the future.
4.3 State crime complexity
From a geographic standpoint, the states of Mexico, Mexico City, and Jalisco emerge as having the highest crime rates in the country. Over the period from 2015 to 2019, these three states accounted for 48% of all crimes committed in Mexico. However, it is relevant to note that the complexity of the crime does not solely capture the overall aggregation of crime in each state. Instead, the complexity analysis aims to standardize the comparison of each state in terms of the types of crimes committed. Thus, a state’s complexity score reflects the prevalence of the crimes committed in that state relative to the entire nation. Specifically, states that demonstrate a higher proportion of complex crimes relative to the whole country will be classified as more complex compared to states where this is not the case. This has significant implications for policy formulation and intervention, allowing policymakers to identify areas of higher complexity and target resources towards more effective crime prevention strategies.
According to the analysis, Tlaxcala, Nayarit, Sonora, Campeche, Sinaloa, Chihuahua, Tamaulipas, Guerrero, Hidalgo, and Michoacán are the most complex states in terms of crime. The complexity of each state is determined by the proportion of homicides, rapes, and organized crime in their total crime rate relative to the national average. Conversely, the states of Mexico, Quer’etaro, and Mexico City are characterized by a basket of less complex crimes due to the high proportion of robberies in their total crimes. This aligns with the observation that regions with higher economic activity tend to experience more robberies. The study found a positive correlation between economic growth, measured by the Quarterly Indicator of State Economic Activity (Indicador Trimestral de la Actividad Económica Estatal, ITAEE), and robberies. Moreover, the correlation between robberies and ITAEE is much stronger than that between high-complexity crimes and ITAEE, suggesting that economic growth is more strongly associated with low-complexity crimes. These findings are presented in tables 3 and 4.
Table 3 Correlation between robbery, high-complexity crimes (HCC) and ITAEE
| ITAEE | Robbery | HCC | |
| ITAEE | 1.00 | ||
| Robbery | 0.41 | 1.00 | |
| HCC | 0.08 | 0.24 | 1.00 |
Notes: The normalization of the Quarterly Indicator of Economic Activity (ITAEE) is based on a standard of 100 for the year 2013, and the average ITAEE was calculated for each state from 2015 to 2019.
Source: Own elaboration.
Table 4 State crime complexity (SCC) (Order from high-complexity to low-complexity)
| 1. Tlaxcala | 11. Guanajuato | 21. Chiapas | 31. Querétaro |
| 2. Nayarit | 12. Zacatecas | 22. Puebla | 32. México |
| 3. Sonora | 13. Colima | 23. Baja California | |
| 4. Campeche | 14. Quintana Roo | 24. Tabasco | |
| 5. Sinaloa | 15. Veracruz | 25. Morelos | |
| 6. Tamaulipas | 16. Baja California Sur | 26. Yucatán | |
| 7. Chihuahua | 17. Nuevo León | 27. Coahuila | |
| 8. Michoacán | 18. Oaxaca | 28. Jalisco | |
| 9. Guerrero | 19. San Luis Potosí | 29. Aguascalientes | |
| 10. Hidalgo | 20. Durango | 30. Ciudad de México |
Source: Own elaboration.
The relationship between low-complexity crimes and economic growth underscores the interplay between economy and crime evolution. The SCC is strongly connected to underlying attributes not examined in this study, such as the institutional environment and justice system, among other factors.
5. Conclusion
This study aims investigate the development of criminal capabilities using the economic complexity methodology and provide an order for the evolution of criminal behavior. The research also offers a framework to describe the distribution and diversification of crime across different regions and insights into the evolution of criminal behavior and effective preventive measures to combat it. This quantitative approach to characterizing criminal behavior contributes to the literature on economic complexity, machine learning applications, and public policy analysis related to crime.
The findings of this study suggest the need for reevaluating conventional approaches to preventive policy and emphasize the importance of understanding the diversification of crime. A proposed strategy to inhibit crime diversification in Mexico entails preventing central crimes in the crime network. The analysis reveals that femicide and rape are the most influential crimes in the criminal network. Thus, preventing violence against women and femicides could lead to a societal environment that discourages criminal activity overall. The results of this research highlight the pivotal role of violence against women in the realm of crime in Mexico and stress the critical importance of preventing femicide. The significance of preventive measures is considerable, as they present the opportunity for a centralized policy approach to protect women against all forms of violence in Mexico.
Moreover, this study presents evidence that raises awareness of the impact and influence of gender violence and advocates for a comprehensive approach to address it. The results encourage us to reflect on our societal behavior in response to these crimes and the factors contributing to the proliferation of gender violence. This work aims to provide tools for preventive action against criminal conduct and, more significantly, to provide evidence of the significance of gender violence in society.

