











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink
Introduction
Graphical representation dates back more than 200 years (Unwin, 2008) For example, (Wainer & Spence, 2005) compiled the work of (Playfair, 1801) who represented data in graphical form. The discipline of statistics uses either real or hypothetical data which can be interpreted graphically (Cleveland, 1985; Tufte, 2001). In any branch of the sciences and, independent of the type of data used to produce it, the ability to read and interpret a graph is indispensable for both students, irrespective of the educational level at which they are studying, and researchers in the making (Glazer, 2011).
Interpreting and reading a graph requires knowledge of statistics, mathematics and real life. In this digital age, information is most often presented graphically (Susac, Bubic, Kazotti, Planinic, & Palmovic, 2018). Newspapers, magazines, billboards, television, the internet and new research generally present results in graph form. Therefore, students should learn to read and interpret graphs based on real data to ensure that they are able to read and interpret a graph throughout their academic life (Monteiro & Ainley, 2007).
The present study seeks to evaluate the difficulties students have with reading and interpreting graphs solely in the academic context. Various studies have identified problems that students at different educational levels have with reading and interpreting graphs (Arteaga, Batanero, Contreras, & Cañadas, 2016; Carrión & Espinel, 2006; delMas, Garfield, & Ooms, 2005; Espinel, 2007; Monteiro & Ainley, 2003; Nolan & Perrett, 2016; Whitaker & Jacobbe, 2017; Wu, 2004). A large-scale study by (delMas et al., 2005) found that high school and college students confuse bar graphs and time plots with histograms, incorrectly use the differences in bar heights in histograms as an indicator of variation, and sometimes incorrectly interpret the horizontal measurement scale as a time scale. Other studies (e.g., Bakker & Gravemeijer, 2004; Ben-Zvi, 2004; Hammerman & Rubin, 2004; Konold, 2003; Leavy, 2006; Makar & Confrey, 2005; McClain, Cobb, & Gravemeijer, 2000) have documented student difficulties with learning to reason about graphical representations of distributions: they focus on particular values such as high and low ones or outliers rather than view a distribution as an aggregate; they have difficulty coordinating ideas of center, spread, density and skewness; they tend to compare slices of data or points, rather than comparing entire entities, taking into consideration overall center and spread.
Cooper and Shore (2008) found that students demonstrated several misunderstandings when judging center and variability of a distribution represented in a graph. Interviews with college students indicated that many incorrectly associated greater variability in the heights of bars in a histogram with greater variability in the distribution, or that only the range was used to compare the variability represented by two histograms. They report that some misunderstandings are related to students’ inability to consider the characteristics of the data represented in a graph, or related to how to compute measures of center such as the mean and median. For example, when estimating the median for a histogram, some students found the midpoint of the values represented on the x-axis. Students also demonstrated difficulty using the relative frequencies of values represented in a histogram when estimating variability, which was also found by (delMas et al., 2005). In addition, Cooper (2018) found that college students have difficulty understanding the underlying structures of different types of graphs that use bars to represent frequency, often erroneously transferring correct conceptions of variability from one type of graph to another.
From the perspective of the authors of this study, few studies have been conducted in Mexico in this area. For example, (Dolores & Cuevas, 2007) carried out a study with students in their last year of primary and secondary school in order to understand their errors in reading and interpreting a graph. Similarly, (Eudave Muñoz, 2009) studied the levels of comprehension of frequency tables and line graphs in students and adults, aged between 15 and 64 years of age. (Ruiz Lopez, 2015) analyzed methods used in third and sixth grade elementary school to teach students the production of bar charts and the interpretation of tables and graphs. Following this line of research, the present study seeks to identify the difficulties that students in the first year of their undergraduate degree in the Economic-Administrative sciences experience when reading and interpreting statistical graphs.
In various countries since the 1980s, statistical education has been systematically promoted at all educational levels, from elementary to post-secondary level through programs, such as the Schools Council Project on Statistical Education in England, or the Quantitative Literacy, Data Driven Curriculum Strand for High School Mathematics and the National Council of Teachers of Mathematics projects in the United States. These projects have incorporated general proposals for statistical education (Cuevas & Ibañez, 2008).
Recently, the International Statistical Literacy Project, an ongoing global endeavor, was established with the fundamental objective of generating educational proposals and cutting edge research in the area of statistics (Sánchez, 2010). It should be noted that significant national endeavors are being conducted in this field in such countries as Chile, Argentina, China, Australia and New Zealand. These are countries which have strongly promoted statistical education, incorporating the latest advances in the area into their national curricula.
In Mexico, the Mexican Statistics Association supports the Red de Investigación y Educación en Probabilidad y Estadística (RIEPE, or Network for Research and Education in Probability and Statistics), which is responsible for disseminating and analyzing academic approaches and research conclusions in the area of statistical education. RIEPE is also charged with coordinating professors, researchers and national collegiate bodies in order to identify the main areas of opportunity for statistical research and education in the country. It seeks to encourage joint work with international academic institutions in order to establish a common agenda that promotes new developments and research in statistical education (RIEPE, 2012).
At the University of Guadalajara, the Centro Universitario de Ciencias Económico Administrativas (CUCEA, or University Center for the Economic-Administrative Sciences) offers 16 undergraduate degree programs in the areas of economics and business. The Statistics I course is taught to all CUCEA undergraduate students, with its thematic content including basic concepts from descriptive statistics which cover graphic representation and basic probability. Per semester, the Statistics I course is taken by approximately 214 students distributed across 10 sections taught by 7 professors. The Statistics I curriculum is updated periodically by the Academy of Statistics, which forms part of the CUCEA’s Department of Quantitative Methods, with the most recent update carried out in 2016. Since 2005 (Del Toro & Ochoa, 2010) a departmental exam comprising 10 multiple choice questions designed by a commission of professors from the Academy of Statistics, has been applied to all students taking the course. The average grade is 50% for the exam.
In order to promote significant and competitive learning in the area of statistics, the CUCEA, through its Department of Quantitative Methods and in coordination with the Academy of Statistics, has organized the annual Statistics I Tournament since 2006, in which students enrolled in the Statistics I course are free to take part. The average Statistics I grade for those competing in the tournament is also around 50%. In 2017, (Coronado, Sandoval, Celso, & Torres, 2018a, 2018b) analyzed the results of the tournament, applying Rasch logistical models with the objective of determining whether this academic event effectively fosters an elevated level of statistical learning and performance and promotes competition among students. Only 13% of the students in the Statistics I competition demonstrated an acceptable level of statistical knowledge. However, the 20-item multiple choice test used in the tournament did not include items to measure student understanding of graphs. The purpose of the current study is to determine the ability of students who completed the Statistics I course to understand and interpret graphical representations in order to guide revision of the course curriculum, as well as the preparation of course instructors.
Method
A Spanish version of the CAOS exam, a validated and calibrated measurement instrument designed for students who have previously taken a basic statistics course at the undergraduate level, was administered to measure CUCEA undergraduate students’ comprehension of histograms (ARTIST, 2006). The exam was designed to evaluate the statistical thinking of undergraduate students who have taken a statistics course, and prioritizes their conceptual comprehension and reasoning of the statistical content, in contrast to the mechanical calculation of formulas and procedures (delMas, Garfield, Ooms, & Chance, 2007). The CAOS test comprises 40 questions, with between 2 and 5 multiple choice answer options for each. A subset of 11 CAOS questions that assess students’ comprehension and graphical reasoning as taught in Statistics I were selected. The assessed learning objective identified by (delMas et al., 2007) for each of the 11 CAOS items can be found in Table 2.
Table 1 Descriptive Statistics for Percent Correct on the 11 Selected CAOS Items (n = 138)
| Statistics | Value |
|---|---|
| Mean | 4.54 |
| Median | 4.00 |
| Mode | 4.00 |
| Standard deviation | 1.40 |
| Variance of the sample | 1.96 |
| Kurtosis | 1.84 |
| Asymmetry coefficient | 1.25 |
| Minimum | 3.00 |
| Maximum | 10.00 |
Source: Prepared by the author based on the sample
Table 2 Percent of Students Who Chose Each Response Option for Each CAOS Item (correct response is in bold type)
| Item | Measured Learning Outcome | Response option (%) | ||||
| 1 | Ability to describe and interpret the overall distribution of a variable as displayed in a histogram, including referring to the context of the data. | Shape only (15) | Normal dist. (22) | General (11) | Complete (52) | |
| 2 | Ability to visualize and match a histogram to a description of a variable (negatively skewed distribution for scores on an easy quiz). | Bell-shaped (10) | Positive skew (9) | Negative skew (30) | Uniform (51) | |
| 3 | Ability to visualize and match a histogram to a description of a variable (bell-shaped distribution for wrist circumferences of newborn female infants). | Bell-shaped (37) | Positive skew (24) | Negative skew (12) | Uniform (27) | |
| 4 | Ability to visualize and match a histogram to a description of a variable (uniform distribution for the last digit of phone numbers sampled from a phone book). | Bell-shaped (27) | Positive skew (35) | Negative skew (16) | Uniform (22) | |
| 5 | Understanding that to properly describe the distribution (shape, center, and spread) of a quantitative variable, a graph like a histogram is needed. | Case-value plot, random order (35) | Case-value plot, Normal dist. shape (43) | Histogram of the variable (4) | Case-value plot, Rank ordered (28) | |
| 6 | Understanding it is not valid to only focus on individual cases when comparing the distributions of two groups. | Valid (41) | Invalid (59) | |||
| 7 | Understanding that considering the difference between the means of distributions for two groups is valid when the distributions are fairly symmetric. | Valid (82) | Invalid (18) | |||
| 8 | Understanding that comparing two groups does not require equal sample sizes in each group, especially if both sets of data are large. | Valid (41) | Invalid (59) | |||
| 9 | Ability to correctly estimate and compare standard deviations for different histograms. Understands lowest standard deviation would be for a graph with the least spread (typically) away from the center. | Bell-shaped, small sd (30) | U-shaped (15) | Uniform (44) | Bell-shaped, medium sd (9) | Bell-shaped, large sd (2) |
| 10 | Ability to correctly estimate standard deviations for different histograms. Understands highest standard deviation would be for a graph with the most spread (typically) away from the center. | Bell-shaped, small sd (23) | U-shaped (39) | Uniform (16) | Bell-shaped, medium sd (9) | Bell-shaped, large sd (13) |
| 11 | Understanding that a distribution with the median larger than mean is most likely skewed to the left. | Bell-shaped (59) | Negative skew (37) | Positive skew (4) | ||
Source: Prepared by the author based on the sample
A population of 214 students that took Statistics 1 in January-July 2018 was asked to complete the 11 CAOS items at the end of the semester. Of the total population, 138 did so voluntarily and anonymously, achieving a high 64.5% participation rate. A sample size of 138 is estimated to produce a 5% margin of error for estimating a 95% confidence interval for a population proportion, which represents a reasonable level of precision. Of the 138 students in the sample, students from all seven professors who taught the class were included. The answers were coded dichotomously, where 1 was given for a correct response and 0 for an incorrect one.
Result and discussion
Table 1 presents the descriptive statistics from the database compiled for the exam applied in the present research. On a scale of 0 to 11, the minimum value obtained was 3 and the maximum was 10, with no student answering all eleven questions correctly. The average score was 4.54, while the median and the mode were equal, with a value of 4. The distribution of the data is asymmetric and positively skewed. This shows that a majority of students scored below the average and that the distribution is leptokurtic, given that there is a large amount of data around the median. It can be seen in Figure 1 that 83% of the students answered less than half of the items correctly.
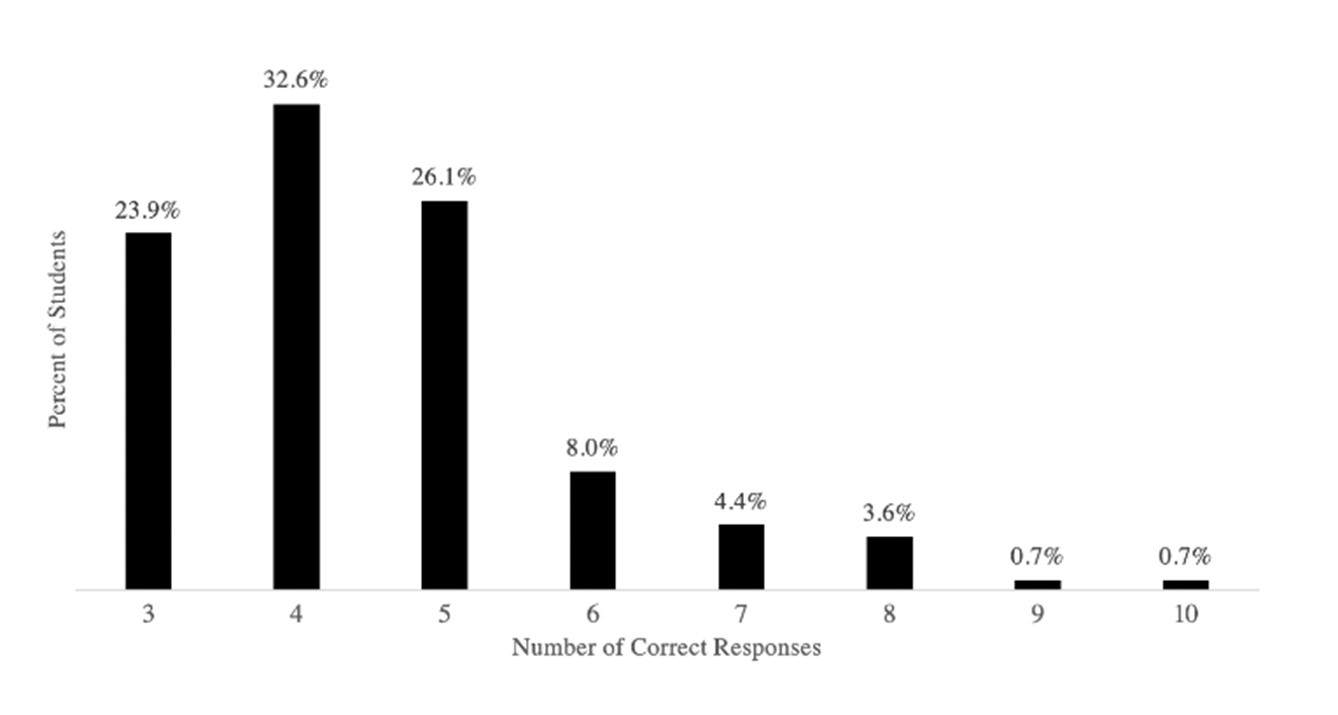
Source: Prepared by the author based on the sample
Figure 1 Distribution of Percent Correct on the 11 Selected CAOS Items (n = 138)
Table 2 presents the percentage of students who selected each response option for each item. Less than half of the students could match the description of a variable to an appropriate histogram (Items 2, 3 and 4). Only 37% of the students were able to recognize a variable description for a bell-shaped distribution (Item 3), with the majority selecting a positively skewed or uniform distribution. Similarly, only 22% of the students correctly identified the histogram for the description of a variable with a uniform distribution (Item 4) compared to the majority who confused it with either a positively skewed or bell-shaped distribution. Less than a third of the students could match a histogram to the description of a variable with a negative skewness (Item 2), with the majority selecting a histogram for a uniform distribution. Related to the Item 2 responses, only 37% demonstrated an understanding that the median being noticeably larger than the mean is indicative of a negatively skewed distribution (Item 11). Thus, many students demonstrated a clear issue with inability to between different types of distribution.
Only 52% of students selected a complete description of a graph (Item 1) and only 4% of students chose the correct response for Item 5, which asked them to identify a graph that represents the distribution, central tendency and dispersion of a variable. Students were more likely to choose one of the three case-value plots, especially one artificially shaped like a normal distribution (43%). This may indicate a preference for symmetric, bell-shaped distributions and a lack of understanding that a graphic representation for the distribution of a variable must represent the shape, central tendency, and dispersion of the variable. It can be inferred from students’ responses to the first five items that they are not familiar with different types of skewness and graph shapes, nor their relationship with central tendency and dispersion measures.
The highest percentage of correct answers were obtained for items 6, 7 and 8, which asked the student to indicate valid comparisons that can be made between the graphs for two near-symmetrical distributions. More than 80% of the students knew that the average could be used to compare two distributions (Item 7), 59% demonstrated an ability to consider each distribution as an aggregate and not focus on individual cases (Item 6), and 59% understood that sample sizes did not need to be equal to compare distributions (Item 8). This may show that the students are more familiar with symmetrical distributions. However, many students indicated it was valid to use special cases in each distribution to make a comparison, or that the sample sizes must be equal in order to make a comparison, even when the sample sizes are large.
Items 9 and 10 presented five different types of graphs in order to assess the students’ interpretation of variation, specifically standard deviation, which they confused with the shape of the distribution of data and the degree to which the values diverge compared to the average. It is interesting to note that for Item 9, 44% of the students associated a low value for standard deviation with a uniform distribution, compared to 30% who correctly related it to a bell curve distribution. This may indicate that many students associate the standard deviation with the variation in bar heights in a histogram and not with the dispersion of the variable. For Item 10, 39% of the students did associate a larger standard deviation with a distribution in which the majority of the data is more distant from the arithmetic mean. However, 45% of the students chose one of the bell-shaped distributions, possibly indicating a preference for a distribution that appears to be normally distributed, and not demonstrating an understanding that a uniform distribution over a similar range has a greater spread in data than a bell-shaped distribution.
Finally, Item 11 presented a table with descriptive statistics for a variable (mean, median, standard deviation, minimum, and maximum) and three types of graphs (bell-shaped, negatively skewed, and positively skewed), and required the students to choose which graph best fits the statistics presented. Thus, despite the fact that the skewness of the distribution can be identified from the statistics (the mean is noticeably less than the median), close to 60% of the students associated them with the near-symmetrical shape. Thus, the students do not appear to be able to interpret a graph when it does not have a symmetrical shape.
The results show that many students in undergraduate programs in the Economic-Administrative sciences experience the following problems in reading and interpreting a bar chart or histogram: they confuse the shape of distribution from a data set; they do not know how to identify small or large standard deviation from a graph; and they can neither clearly identify skewed distributions nor relate them to their central tendency and dispersion measures. On the other hand, many students do make satisfactory interpretations when asked to compare symmetrical graphs with different arithmetic means and standard deviations; moreover, when presented with symmetrical distribution, they do satisfactorily describe both the central tendency and dispersion measures, as well as atypical values.
These results may be due to various probable causes, such as students not being taught the different forms of data distribution or their relationship with central tendency and dispersion measures and reveal that more emphasis may be placed on symmetrical than on asymmetrical distributions. Another cause could be the lack of teacher training in the area of graphical representation, which may be explained by the different types of pedagogical preparation of those teaching the statistics courses.
Conclusion
In this study, the CAOS test was applied to undergraduate students who had taken a descriptive statistics course to assess their statistical thinking. The results show that a high percentage of students had problems recognizing what kind of distribution they were analyzing. Also, they were confused with how to calculate the skew with measures of central tendency or dispersion. There could be another factor that affects their performance in statistical thinking. For instance, there could be deficiencies in the way they are taught statistics.
Therefore, it is recommended that course instructors receive pedagogical training in research-based teaching methods that have been shown to develop students’ ability to understand and reason with graphical representations. For example, methods developed by Bakker (2004) that have students go through a series of exercises where they “grow a sample” have been shown to promote aggregate and distributional thinking in students. Cooper and Shore (2010) have suggested visual aids that may help students visualize and understand variability as it is represented in histograms and value bar charts. Garfield & Ben-Zvi (2005) provide a conceptual model for developing students’ reasoning about variability. Two components of the model related to understanding variability represented by graphic representations (describing and representing variability; recognizing variability in special types of distributions) provide instructional goals for teaching and assessment. A teaching experiment conducted with preservice teachers by Leavy (2006) indicated that students who used graphic representations, in addition to summary statistics, to compare distributions of data demonstrated increased attention to global trends in distributions and more success in communicating the use of graphical representations towards the end of a 15-week course. Hopefully, students’ understanding of and reasoning about graphical representations can be developed through better preparation of course instructors.
Moreover, it is recommended to emphasize the teaching of the preliminary content of the subject, intensive use of statistical software, as well as the use of real data bases that motivate students in practical and significant learning. As a possible extension of this work, to be analyzed in the future, is the reading and interpretation of statistical graphs in the classroom, teaching methodologies, the teaching itself and the academic curriculum to determine whether one of these factors is failing or a combination of multiple factors. At the same time, a comparative study could be done of graph interpretation between students of an economic-administrative background and students from other undergraduate majors or other institutions of higher education.

