ANEXO METODOLÓGICO
El modelo aplicado resulta de una adaptación ya propuesta por Salvia y Tuñón (2007) para el modelo de TAM (2006), y puede ser escrito de la siguiente manera:
[1] 1hwi + β0 + β1G1
donde 1nw es el logaritmo del ingreso por hora corregido del i-ésimo individuo, G es una variable dummy con valor 1 para los varones, y β0 y β1 son coeficientes a estimar. En dicho modelo si β1 es significativamente diferente de cero, estaremos en presencia de una brecha de ingresos por género. El signo de este coeficiente indica quiénes ganan más: los varones o las mujeres y permite estimar la diferencia porcentual observada.
Nuestro primer modelo reemplaza la variable género por la variable sector/segmento, ambas convertidas en variables dicotómicas como se detalla en la tabla más abajo.
El segundo modelo constituye una generalización de este modelo a través de una ecuación del tipo:
[2] lnW1 + β0 + β1G1 + β2H1 + β3I + OΩ
en esta ecuación, H es una matriz que incluye las dotaciones de capital humano de los trabajadores (operacionalizada a partir de la educación) y I es el vector de parámetros a estimar asociado a dicha matriz a partir de las característica socio-demográficas (sexo, edad y ubicación geográfica). En un tercer modelo se incluye a la ecuación la pertenencia al segmento primario/estable de empleo, y asume la siguiente forma:
[3] 1nWi + β0 + β1G1 + β2H1 + β3Ii + β4J + OΩ
donde J representa a la pertenencia al segmento primario. Finalmente, en un cuarto modelo incluimos la interacción entre la pertenencia al sector informal y al segmento precario/marginal del mercado de trabajo. En esta última ecuación, los efectos remanentes del componente G indican puestos estable dentro del sector informal.
[4] 1nWi + β0 + β1G1 + β2H1 + β3Ii +β4J + β5K + OΩ
donde K representa la interacción sector * segmento.
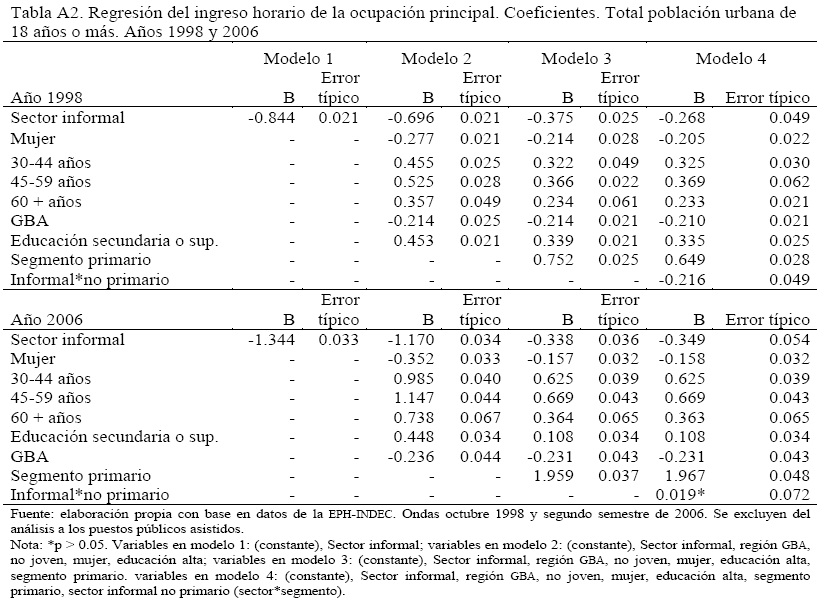
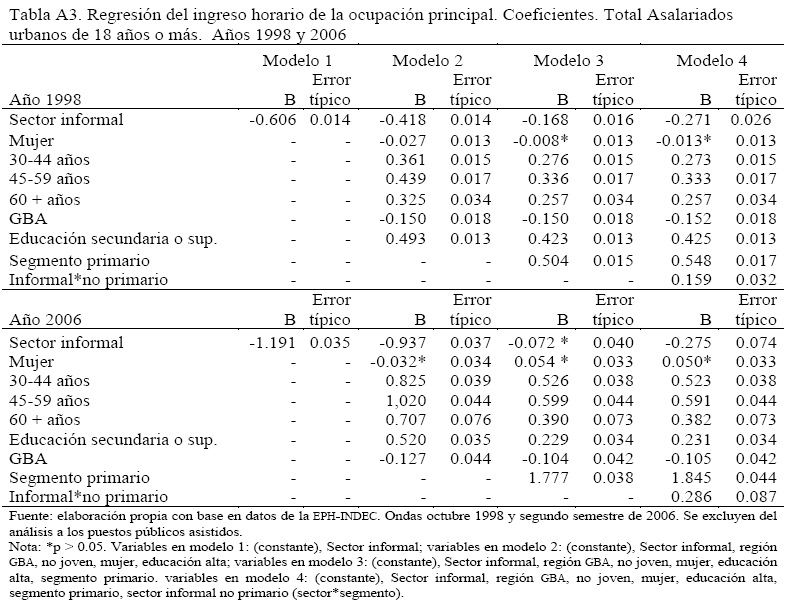
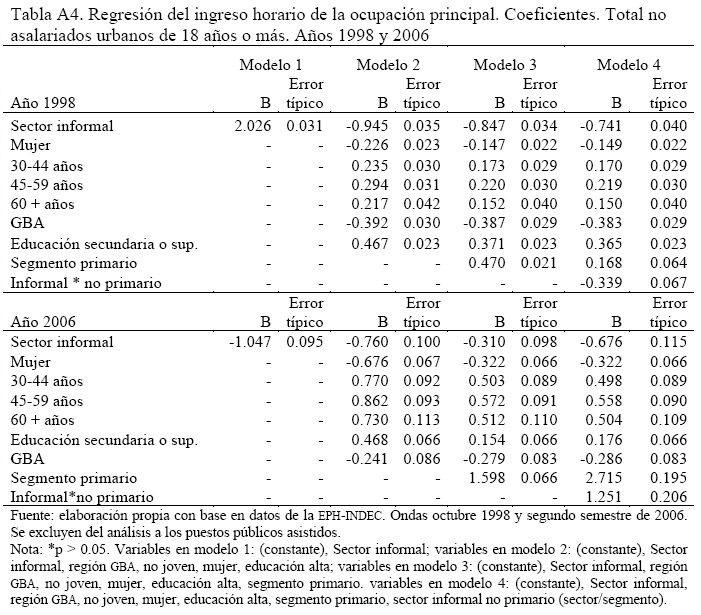
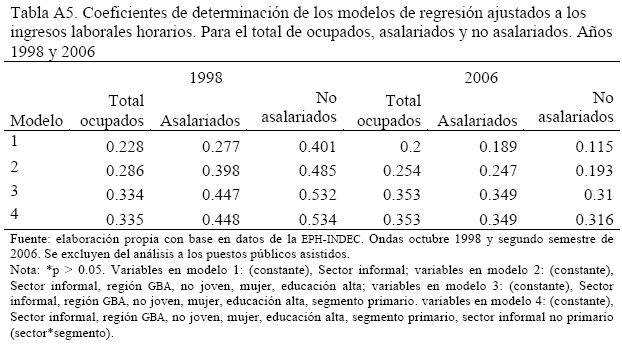
Un detalle de las variables independientes incluidas en las regresiones puede encontrarse en la Tabla A.1.
Los resultados examinados en el presente artículo surgen de procesamientos de la Encuesta Permanente de Hogares del Instituto Nacional de Estadísticas y Censos, (EPH/INDEC): ondas de octubre de 1998, 2001 en su modalidad "puntual" y segundos semestre de 2003 y 2006 en su modalidad continua. Además, se excluyeron los aglomerados incorporados después de octubre de 1998. Finalmente, se utilizó una corrección por empalme para volver comparables las mediciones (Salvia et al, 2008).
Para las regresiones se consideró al universo de ocupados que declaran ingresos laborales horarios y excluyendo a los ayuda familiar sin salario. Se prefirió no incluir a quienes no declaran ingresos ya que para su estimación se emplean habitualmente las variables cuya importancia queremos analizar en este documento, lo que podría aumentar artificialmente el poder explicativo de nuestro modelo. Por las mismas razones, se prefirió modelar sin ponderar los datos finales de la base.
Los coeficientes (β) generados a través del ajuste de los modelos 1 y 2 para estimar el efecto sector y segmentos sobre los ingresos laborales horarios fueron empleados para calcular las brechas de los ingresos logarítmicos. Aplicando algunas porpiedades de los logaritmos, la brecha puede expresarse como: