











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1 Introduction
An Event in social media is a popular topic that matters to the online community. Participation of more users towards an event makes it popular and attracts more information. Event in Twitter becomes trendy, interesting and popular in a short span of time due to the large shared information. Thus, Twitter becomes a promising source to get the most recent news or updates of any real-time event [19]. In recent times, Twitter has defeated any traditional news media in reporting information about many ongoing events like Amarnath terror attack, Kashmir flood situation, earthquake and many more. Increasing popularity of Twitter is attracting large volume of shared information for most popular events. However, a great amount of the shared information related to an event is irrelevant or non-informative to the event. Moreover the style of writing in Twitter is also very casual in nature and pose difficulties to condense the most relevant and informative information [26]. Thus, conceptualizing informative, relevant and trustable tweets of a specific event is a challenging research problem. Different research works and Twitter itself devise various state-of-the-art ranking strategies to list down relevant, trendy and informative tweets. However, these strategies often face difficulties to determine priority of a tweet for understanding an event due to several reasons. The reasons are: first, degree of informativeness and relevance measure of two tweets may differ for different events having thematic distinctiveness. For example, event on crisis scenarios include huge number of tweets citing specific information from effected different locations where most of them are very important to understand the scenario as well as to provide facilities. But, it is very difficult to identify the most important tweet among them. For example,
Tweet: @xx : Elderly & kids about 25 people stuck in Zargar lane, opposite Beeco store, 386/B Jawahar Nagar Please help #KashmirFloods
Tweet: @xx 200 female resident doctors of Lal Ded Hospital hostel , karan nagar require immediate help . No phone connectivity . #KashmirFloods
In above two examples, both the tweets are bearing important information. But identifying more important tweet is a difficult task. On the other hand an entertainment event contains some specific facts about the event while which leave the ranking task comparatively easy.
Second, presence of maximum number of Twitter specific words like hashtags, user mentions and url in a tweet may return good matching score with the query but carries very less information regarding the event. For example, in the following tweet out of 10 tokens 6 tokens are hashtags and url.
Tweet: #Jallikattu at the world famous #Alanganallur #JallikattuForever #TNyoungsters #madurai https://t.co/wBsHmlLSvR.
Third, an information related to an event may be shared through different expressions which are semantically similar. So, re-tweet is not the only measure to represent the most important or popular content always. Moreover, spammers or number of false user can easily propagate false or fake information by re-tweeting to highlight a particular information. For example, following tweets share similar content without re-tweeting each other.
Tweet 01: Proud ! @xx RT @timesnow Army wont move back to the barracks till the last man is brought to safety : Gen Dalbir Singh , #KashmirFloods
Tweet 02: Army Chief : Indian Army will not move back to the barracks till the last man is rescued . #KashmirFloods #JKFloodRelief
Forth, tweets are often short text without proper punctuation [27] and standard grammar. Due to that, formation of query to retrieve relevant tweets is a difficult task. Moreover, only hashtag for relevant tweet extraction is also not a reliable way as it may return irrelevant tweets to the event or tweets related to other event. For example, following tweet is fetched for the event Kashmir Flood but contains no information to describe the event.
Tweet: @xx : Kejri was found having hand in gloves with Sheila Mausi during the pathetic flood situation in Kashmir #KashmirFloods
To provide potential solution of these problems, we focus on informativeness and relevance of tweet content for ranking them. In our work, informativeness means degree of information acceptability which can explain the event understandable to maximum people and relevance means degree of content closeness to the event. In this research paper, our aim is to return a list of topic-focused tweets according informativeness and relevance [14] while non-relevant and non-informative tweets are filtered out of the list. Our contributions in this paper are as follows:
We propose a ranking model to rank tweets of an event by considering relevance and informativeness of each tweet towards the event. we compute content popularity based on content similarity measure, distribution of top keywords of the event, distribution of top hashtags and ratio of unique content words.
We evaluate the performance of our approach by comparing with the baseline ranking strategies. Through experiment result, we show that the proposed method improves the ranking task over the baseline strategies.
Rest of the paper is organized as the following. Next section describes relevant promising research works. Section 3 presents proposed approach followed by experiment setup and result in section 4. Section 5 reports an analysis on performance and errors of the approach. Finally, section 6 concludes the paper with a note on scope of future work.
2 Related Work
In this section we discuss relevant research work on tweet ranking, content informativeness and content relevance measure. Most of the earlier promising research works on tweet ranking proposed ranking model using learning to rank algorithms. Those models are developed based on the analysis of tweet content [28,22], user credibility [33,35,12,31] and Twitter specific features [8]. Twitter content analysis is done based on the length of tweet, unique words count and query based similarity scores while follower count of user and account authenticity defines user credibility. Twitter specific features are restricted to tweet text like URL, Hashtag, re-tweet and out of vocabulary words count.
The work by Tao et al. [30] proposed two kinds of features like topic-dependent and topic-independent features to extract most relevant tweets. Topic-dependent features are keyword relevance and semantic relevance while topic-independent features are syntactical and semantic characteristics of tweet. Syntactical features are entities embed in a tweet message like URL, Hashtag, user mention and word count. Semantic feature are related with the meaning of the content, semantic diversity and tweet sentiment. URL in the tweet links to external information source which signifies valid reference and increases the possibility of more quality contents [2]. Huang at al. [15] used this feature and tweet-user relations for ranking most relevant tweets. Often URL linked external information which. The URLs embed into tweet in regular or shortened form called tinyurl. Tinyurl is a precise form of regular url which provides short aliases for redirection of long URL. The work by Chang et al. [6] utilized the presence of shortened URL link in the tweet to identify most recent and high-quality tweets for ranking them. When a tinyurl shares among several tweets then inclusion of these contents improves tweet index quality. Ravikumar et al. [23] proposed a ranking method based on the relevance and trustworthiness of tweet using two kinds of features like trustworthiness of the tweet source and trustworthiness of the tweet content. First feature value depends on user information, tweet content and the page information referred to in the tweets. The later one estimates by analyzing independent corroboration of tweet content by other tweets. Considering these two measures a graph constructs where trustworthiness of the tweet source represents vertices and trustworthiness of the tweet content represents edges to list top tweets.
Ranking task is very close to assessing credibility of information. More credible information gains better rank to understand any event. Gupta et al. [10] proposed an approach to measure credibility of information in tweet based on support vector machine algorithm and Pseudo Relevance Feedback approach. Credibility is computed based on features like number of unique characters, swear words, URL, follower count. In the later work [11] authors developed a ranking system based on 5 categories of features like tweet meta-data, linguistic features, user features tweet content features and external resource features. The work further reports that the performance of ranking model differs for different genre of training and testing dataset. Ross and Thirunarayan [24] proposed a ranking strategy for news tweets using tweet credibility and newsworthiness. The approach incorporate a measure on tweet sentiment and topic overall sentiment for ranking of tweets in addition of existing standard features. In a recent work proposed by Carvalho et al. [4] used Fuzzy Fingerprints for extracting most relevant tweets for an event. Fuzzy fingerprint for a given topic is generated from the most frequent distinct words in classified tweets (classified using hashtag) and by fuzzifying each top word list. Tweet relevance is measured based on the similarity score between candidate tweet fuzzy fingerprint and the set of fuzzy fingerprint of all classes.
Our research work focused on informativeness and relevance by analyzing event's top keywords, content similarity and ratio of unique words in addition of existing standard features.
3 Proposed Approach
Our ranking approach consists with two components, namely, extraction of most relevant and informative tweets and ranking of tweets. In the following subsections we discuss each component of our approach in detail.
3.1 Extraction of Relevant and Informative Tweets
We formalize the problem of relevant and informative tweets extraction as a multi-class classification problem. We adopt features from the related promising works [5,10,11,18,34,36] and add more features like distribution of top keywords in tweet, similar tweet count, ratio of unique words and top hash tag counter to measure content richness and relevance more precisely. Detail of the features descriptions are given below.
3.1.1 Content Relevance and Richness Features
Top keyword count: Presence and count of top keywords of an event in a tweet plays crucial role to determine its relevance with the event [4]. Latent Dirichlet Allocation (LDA) is one of the most commonly used techniques [13] for keywords extraction of tweets. We used the toolkit1 to extract top keywords for a Twitter event and count presence of top keywords in each tweet.In our work we extracted top 50 words for an event and count distribution of those words in a tweet. This feature returns an integer value.
Word to vector similar tweet count: Similarity of contents estimates the popularity of documents in the corpus [29,3,32,1]. In our case, it measures how many tweets are similar in content for a tweet in an event. Using pre-trained word vectors [21] of Twitter2 with 100 dimension and using the approach proposed in [25], we calculate similar tweet counts.
Length of tweet: Length of a tweet represents the number of words it contains. Often longer sentences have richer information than short sentences. Thus, tweet length is an important feature to represent content richness.
Unique words count: More number of unique words in a tweet represent more significant information regarding the event. We drawn this feature to determine content richness towards the event.
Ratio of unique words: A tweet may includes number of Hashtag, user mention and URLs. The ratio of all these tokens with the unique words in a tweet is an important feature to decide content richness of that tweet. This feature returns value ranging from 0 to 1.
Top hash tag counter: A tweet may includes number of hashtags. However all that hashtags may not be relevant to the desired event. Often most frequent hashtag of an event is the most relevant hashtag. So, we have taken the presence of top hashtag of the event in a tweet to determine the relevance. Using the toolkit3, we extracted top two hashtags for an event and extracted feature value (0/1/2) for each tweet. It returns count of top two hashtags presence in tweet.
3.1.2 Twitter Specific Features
We exploit Twitter specific characteristics to determine relevance and informativeness of a tweet.
Hash tag count: Hashtag property of Twitter is used to facilitate binding of tweets for an event or discussion. This feature return number of hashtags present in a tweet.
Hash tag counter: This is a binary feature which indicates that whether a given tweet includes any hashtag or not.
Re-tweet count: Re-tweet count is defined as the number of times a tweet is repeat with a tag "RT".
URL counter: This feature represents 1 when a tweet contains at least one URL, otherwise 0.
User mentions count: This represents the number of times a user is referred to in a tweet.
3.1.3 Classifier Selection
We propose Logistic Regression (LR) classifier for our multi-class classification problem. We also experimented with other classification algorithms like SVM (implemented as Sequential Minimal Optimization classifier (SMO) in our used tool) and Naive Bayes (NB) classifier to evaluate the performance of our approach. Detail of the experiment and performance is discuss in experiment setup and result section.
3.2 Ranking of Tweets
After classification and obtaining the relevant and informative tweets, we adopt learning to rank algorithms to rank tweets of events. Our ranking algorithm trained on the following features along with the features discussed in section 3.1.1 and 3.1.2.
Followers count: Every user in Twitter is follows or followed by a number of users called followers to tract their updates and also to be followed own updates. More number of followers of an user defines more credibility of that user.
Like count: Like facility in Twitter determines level of appreciation of the tweets content.
List score: This feature represents the number of lists a user associated with. If any user becomes member of a list, then the possibility of shared information to be more relevant and important is more.
4 Experiment Setup and Result
4.1 Dataset
Twitter users can share various information like status update, conversation, news and personal views or comments on any real time events. In our current research work, we concentrated on event-focused English tweets that are informative to a general class of users, such as news or any real-time events. For example, Amarnath terror attack, Asifa murders case, Kashmir floods situation and many more.
We have collected English tweets for 25 trending events using Twitter4j4 during the period from January to October, 2017. The events are varies from natural disaster (i.e., Kashmir Flood, UP flood), politics (i.e., By-election result, Assam election), national and international breaking news (i.e, Amarnath terror attack, Bashirhat riots), entertainment events (i.e, iTune festival, Golden gloves award ceremony) and technology relevant events (i.e., iPhone launch). For each event, top 1500 tweets are retrieved using tweet fetching tool. To extract desired event relevant tweets, we used commonly known hashtags like #AmarnathTerrorAttack, #Asifamurders, #AsifaJustice, #KashmirFlood, keywords and key phrases like Amarnath attack, Asifa murder case, Kashmir flood and Kashmir flood situation pertaining to the events. The retrieving process returns English as well as Non-English tweets containing query words or hashtags. So, we cleaned obtained tweets by filtering out Non-English and short tweets with less than 3 words. Re-tweeting facility in Twitter generates huge amount of similar content frequently [37] leaving difficulties towards tweet processing. In this work, we removed all the re-tweets to diversify top ranked tweets. Final statistics of the corpus is reported in below table.
Table 1 Statistics of the corpus
| Event (nos.) |
Tweet (nos.) |
Max-min /Event |
Token (nos.) |
Max-Min /Tweet |
|---|---|---|---|---|
| 25 | 6578 | 321/87 | 108803 | 27/5 |
To list tweets according to informativeness and relevance to the event, we follow two steps manual annotation process. In the first step, all the tweets are manually annotated following the annotation guideline proposed in [10,11,24]. In our work, we slightly modify 5 point scale as proposed in earlier works into 4 point scale by merging point 2 and 3. The reason behind is that non-relevant and non-informative contents are equivalent in our ranking task. For manual annotation process, we employed two human annotators who are native English speaker. We also provide brief information of each event to the annotators. Both the annotators annotated each tweet with one of the following point: (4) Tweet is relevant and contains information, (3) Tweet is relevant and seems contain information, (2) Tweet is relevant but contains no information and (1) Tweet is not relevant. When the point difference between annotators is 1, the lower point is selected while more than 1 point difference, both the annotators re-annotated those tweets after discussion on disparities and the lower point is selected. Table 2 shows the average distributions of all points for all the events.
In the 2nd step of annotation, informative and relevant tweets labelled as point 2 and 3 are assigned to both the annotators to rank top 20 tweets according relevance and informativeness. Based on the brief information of the event, annotators select top 20 tweets for each event and rank considering informativeness and relevance of the tweets. But this annotation process returns very low agreement score due to the different views of the annotators towards the event which is very natural. Thus, we reset the annotation process in a controlled environment and provide set of queries for each event. Annotators are requested to understand the expected outcome of queries to rank a tweet accordingly. In this phase, we achieved better inter-annotator agreement with a Kappa [7] value of 0.6801 and prepared gold standard data for further experiment.
4.2 Experiment and Result
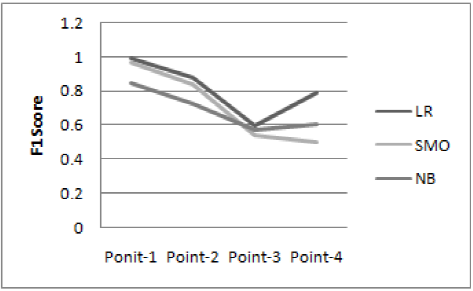
Our ranking approach is a two phase based approach. In the first phase, we experimented with three classification algorithm to extract most informative and relevance tweets for an event as discussed in section 3.1.3. The classifiers executed in WEKA 3.8 machine learning tool5. Detail result of ten-fold cross-validation for each experiment is shown in table 3. Tabulation result and the graph in figure 1 show that Logistic Regression classifier performs better than the other experimented classifiers for all categories. Classifier shows highest F1 score of 0.97 to identify non-informative and non-relevant tweets. Average deviation of F1 score between the best and the least perform classifier is 10.75. Detail analysis of the classifier performance is discuss in Error Analysis section.
Table 3 Experimented classifiers performance
| Classifier | Categorical F1 Score | |||
|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |
| LR | 0.97 | 0.88 | 0.60 | 0.79 |
| SMO | 0.95 | 0.84 | 0.54 | 0.50 |
| NB | 0.85 | 0.73 | 0.57 | 0.60 |
In the 2nd phase, we propose a ranking model by using a RankSVM algorithm introduced by Joachims [17] to rank only informative and relevant tweets. Our ranking model is trained on all features we extracted from our dataset. We used the RankSVM toolkit6 for our experiment work. We also experimented the performance of the model by comparing with another learning to ranking tool 7 developed based on LambdaMART algorithm (LA) [9]. Evaluation of the algorithms is done using Mean Average Precision (MAP) and Normalized Discount Cumulative Gain (NDCG) [16] evaluation metrics. MAP evaluates the preference of one tweet than other, while NDCG describes how useful is a tweet. Detail result of our experiment is shown in table 4. Performance evaluation is reported in respect of top 20 (@20), top 15 (@15) and top 10 (@10) tweets. Both the metrics score show that RankSVM list the most important tweets more accurately than LambdaMART algorithm for all the range of top tweets. Result also shows that ranking of top 10 tweets is done more accurately than ranking top 20 tweets even though the deviation is very less (0.2 for NDCG and 0.6 for MAP). The summary of both algorithm performance in terms of NDCG evaluation metric is reported in figure 2.
Table 4 Performance of ranking models
| Evaluation Metrics |
Approach | ||
|---|---|---|---|
| RankSVM | LA | ||
| @20 | 0.89 | 0.55 | |
| MAP | @15 | 0.89 | 0.57 |
| @10 | 0.95 | 0.62 | |
| @20 | 0.73 | 0.55 | |
| NDCG | @15 | 0.75 | 0.56 |
| @10 | 0.75 | 0.55 | |

We also experimented our model with one baseline ranking algorithm. We choose TextRank ranking algorithm as baseline algorithm which already has shown success when applied to sentence or document ranking [20] in previous research works. Comparative result of the algorithm and our approach is reported in table 5.
5 Error Analysis
An in-depth analysis of the system performance reveals that, identification of tweets with point 4 and point 3 is challenging and to distinct them is more challenging. The reasons behind the difficulties may be due to the fact that the text in tweets are very sparse in nature. Users often use uncommon acronyms, abbreviations and distinct terms and grammatical structure to represent same expression in different ways. More extensive semantic analysis of tweet text may help to identify semantic closeness between tweets more accurately. In our experimental work, we observe that the feature ratio of unique words in a tweet significantly helps the system to find non-informative tweets (point 1) very well. More informative tweets include comparatively lower score for this feature. Some exceptional tweets are also there who hold good score for ration of unique words but are non-informative. For example,
Tweet: #modi100days over & no signs of #BlackMoney . I'll catch a bhakt & pour a bucket full of cow dung on them today . That's my #CowDungChallenge
However, our system successfully identified most of the non-informative tweets (point 1) where each of them have a higher score for this feature.
During ranking of top 20, 15 and 10 tweets for an event, our model shown the best performance for ranking top 10 tweets. For ranking more number of tweets, the performance of our model slightly degraded. Performance analysis of our ranking model reveals following observations. One, some tweet included in the top ranked list due to the maximum score of one or two features even though the tweet is not that much informative. For example, following tweet is taken from the event "#Gazaceasefire". The tweet contains top ranked hashtag, one event keyword and re-tweeted 52 times. Hence, even though the tweet is less informative it is still placed in top ranked list by defeating other more informative tweets. For example,
Tweet: Here are some incredible photos of cease-fire celebrations #Gazaceasefire http://t.co/onwmJDnyd8 http://t.co/i2DdR2rKPW.
Two, events in the social media attracts different volume of user participation depending on the popularity and association among the users. More popular events concern with more users, influential user and diverse information. These features lead to better weight towards informative tweet and thus make ranking task easier. But, in case of comparatively less popular events, informative tweet's features weight become close to each other. Thus selection of top tweets for a ranked list becomes ambiguous.
6 Conclusion and Future Work
We have drawn a set of new features and developed a ranking model by following a two-step approach. Proposed approach first extract most relevant and informative tweets and then rank them accordingly. We proposed features like distribution of event top keywords in tweet, count of similar tweets, distribution of top hashtags and ratio of unique words in tweet to identify most informative and relevant tweets in addition of standard features drawn from promising previous works. Our developed ranking model reports comparable performance for event-focused English tweets.
Social media poses great challenges to identify trust information [38]. Trustworthiness of tweets is very difficult to measure. Malicious users can easily pass false or irrelevant information via social media which can go undetected by most of the ranking approach. As a future scope of this work, the ranking model can be more robust by incorporating or enhancing trustworthiness measure of tweets or users.

