











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1 Introduction
The principle known as Distributional hypothesis is derived from the semantic theory of language usage, the meaning of words that are used and occur in the same contexts tend to have similar meaning [7]. The claim has the theoretical basics in psychology, linguistics, or lexicography [4]. This research area is often referred to as distributional semantics. During last years it has become a popular. Models based on this assumption are denoted as distributional semantic models (DSMs).
1.1 Distributional Semantic Models
DSMs learn contextual patterns from huge amount of textual data. They typically represent the meaning as a vector which reflects the contextual (distributional) information across the texts [35]. The words are associated with a vector of real numbers. Represented geometrically, the meaning is a point in a k-dimensional space. The words that are closely related in meaning tend to be closer in the space. This architecture is sometimes referred to as the semantic space. The vector representation allows us to measure similarity between the meanings (most often by the cosine of the angle between the corresponding vectors).
Word-based semantic spaces provide impressive performance in a variety of NLP tasks, such as language modeling [2], named entity recognition [14], sentiment analysis [11], and many others.
1.2 Local Versus Global Context
Different types of context induce different kinds of semantic spaces. [26] and [20] distinguish context-word and context-region pproaches to the meaning extraction. In this paper we use the notation local context and global context, respectively. Global-context DSMs are usually based on bag-of-words hypothesis, assuming that the words are semantically similar if they occur in similar articles and the order in which they occur in articles has no meaning. These models are able to register long-range dependencies among words and are more topically oriented.
In contrast, local-context DSMs collect short contexts around the word using moving window to induce the meaning. Resulting word representations are usually less topical and exhibit more functional similarity (they are often more syntactically oriented).
To create a proper DSM a large textual corpus is usually required. Very often Wikipedia is used for training, because it is currently the largest knowledge repository on the Web and is available in dozens of languages. The most of current DSMs learn the meaning representation merely from the word distributions and does not incorporate any metadata which Wikipedia offer.
1.3 Our Model
In [34] we show a different possibilities, how to incorporate global information and in this article we will summarize the work, choose ideal setup and test the model with highly inflected language. We combine both the local and the global context to improve the word meaning representation. We use local-context DSMs Continuous Bag-of-Words (CBOW) and Skip-Gram models [21].
We train our models on English and Czech Wikipedia. We evaluate it on standard word similarity and word analogy datasets.
1.4 Outline
The structure of article is following. Section 2 puts our work into the context of the state of the art. In Section 3 we review Word2Vec models on which our work is based. We define our model in Section 5 and 4. The experimental results presented in Section 7. We conclude in Section 8 and offer some directions for future work.
2 Related Work
In the past decades, simple frequency-based methods for deriving word meaning from raw text were popular, e.g. Hyperspace Analogue to Language [18] or Correlated Occurrence Analogue to Lexical Semantics [27] as a representatives of local-context DSMs and Latent Semantic Analysis [16] or Explicit Semantic Analysis [8] as a representatives of global-context DSMs. All these methods record word/context co-occurrence statistics into the one large matrix defining the semantic space.
Later on, these approaches have evolved in more sophisticated models. [21] revealed neural network based model CBOW Skip-gram that we are going to use as our baseline to incorporate Global context. His simple single-layer architecture is based on the inner product between two word vectors (detailed description is in Section 3). [25] introduced Global Vectors, the log-bilinear model that uses weighted least squares regression for estimating word vectors. The main concept of this model is the observation that global ratios of word/word co-occurrence probabilities have the potential for encoding meaning of words.
2.1 Local Context with Subword Information
Above mentioned models currently serve as a basis for many researches. [1] improved Skip-Gram model by incorporating a sub-word information. Simirarly, in most recent study [30] incorporated a sub-word information into LexVec [29] vectors. This improvement is especially evident for languages with rich morphology. [17] used syntactic contexts automatically produced by dependency parse-trees to derive the word meaning. Their word representations are less topical and exhibit more functional similarity (they are more syntactically oriented).
[13] presented a new neural network architecture which learns word embeddings that capture the semantics of words by incorporating both local and global document context. It accounts for homonymy and polysemy by learning multiple embeddings per word.
Authors introduce a new dataset with human judgments on pairs of words in sentential context, and evaluate their model on it. Their approach is focusing on polysemous words and generally do not perform as well as Skip-Gram or CBOW.
3 Word2Vec
This section describes Word2Vec package which utilizes two neural network model architectures (CBOW and Skip-Gram) to produce a distributional representation of words [21]. Given the training corpus represented as a set of documents
D
. Each document (resp. article)
We use training procedure introduced in [22] called negative sampling. For the word at position i in the article
where
Considering articles
According to [21], CBOW is faster than Skip-Gram, but Skip-Gram usually perform better for infrequent words.
4 Wikipedia Category Representation
Wikipedia is a good source of global information. Overall, Wikipedia comprises more than 40 million articles in 301 different languages. Each article references others that describe particular information in more detail. Wikipedia give more information about an article that we might not see at the first moment, such as mentioned links to other articles, or at the end of the article there is a section that describes all categories where current article is belonging. The category system of Wikipedia (see fig. 1) is organized as an overlapping tree [31] of categories1 with one main category and a lot of subcategories. Every article contains several categories to which it belongs.
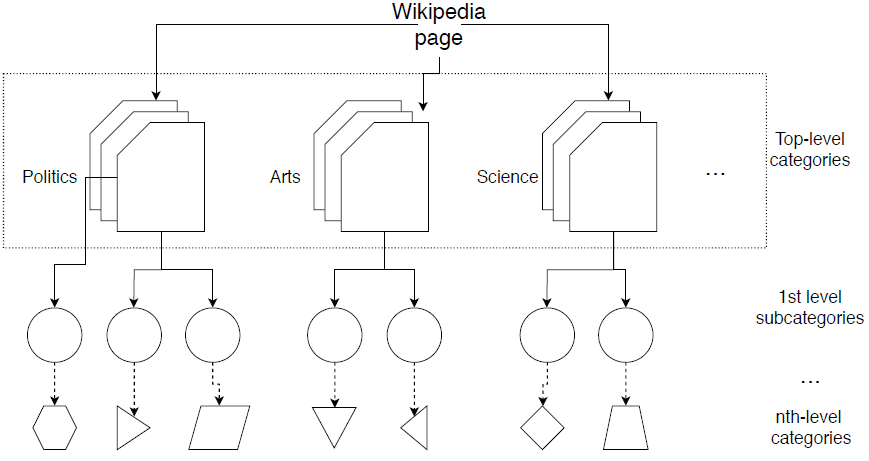
Categories are intended to group together with pages on similar subjects. Any category may branch into subcategories, and it is possible for a category to be a subcategory of more than one 'parent' category (A is said to be a parent category of B when B is a subcategory of A)[31]. The page editor uses either existing categories, or create one. Generally the user-defined categories are too vague or may not be suitable to use them in our model as a source of global information. Fortunately, Wikipedia provides 25 main topic classification categories for all Wikipedia pages.
For example the article entitled Czech Republic has categories Central Europe, Central European countries, Eastern European countries, Member states of NATO, Member states of EU, Slavic countries and territories and others. Wikipedia categories provide very useful topical information about each article. In our work we use extracted categories to improve the performance of word embeddings. We denote articles as aj and categories as xk (see fig. 2).
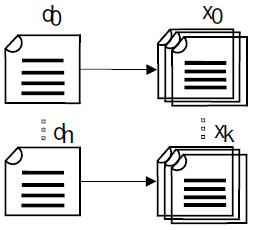
5 Proposed Model
Some authors tried to extract a more concrete meaning using Frege's principle of compositionality [24], which states that the meaning of a sentence is determined as a composition of words. [36] introduced several techniques to combine word vectors into the final vector for a sentence. In [3] experimented with Semantic Textual Similarity, from the tests with words vector composition based on CBOW architecture, we can see that this method is powerful to carry the meaning of a sentence.
Our model is shown in Figure 3. We build up the model based on our previous knowledge and believes that Global information might improve the performance of word embeddings and further lead to improvements in many NLP subtasks.
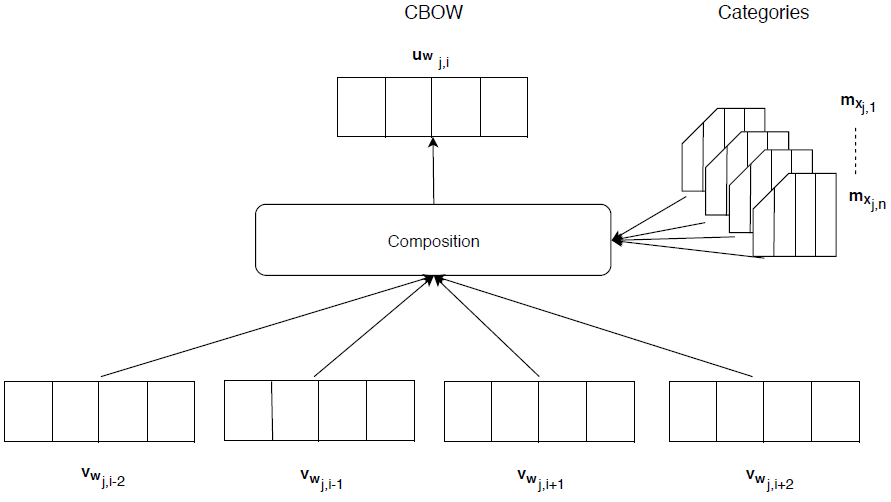
Each article
CBOW model optimize following objective function:
Skip-gram model optimize following objective function:
Visualization of the CBOW is presented in Figure 3. Visualization of the Skip-gram is presented in Figure 4.
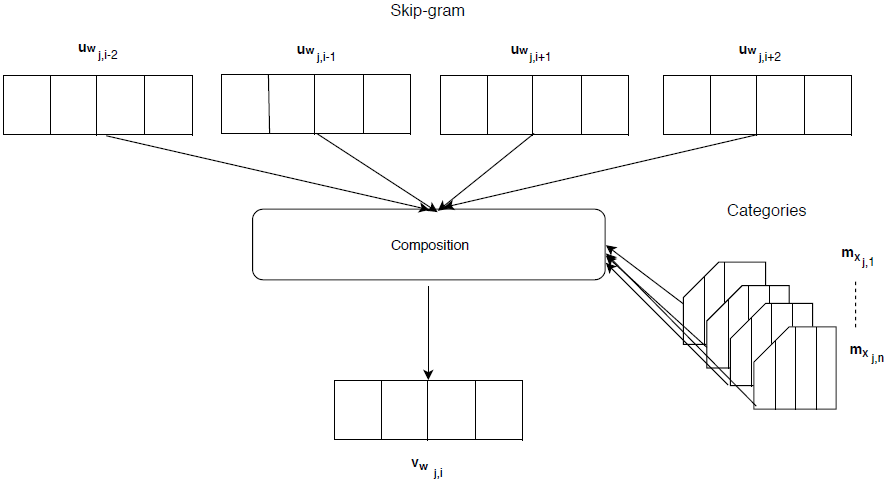
We tested with CBOW and Skip-gram architectures enriched with categories that are shown in Figures 3 and 4. The CBOW architecture is generally much faster and easier to train and gives a good performance. The Skip-gram architecture is training 10x slower and was unstable during our setup with categories.
5.1 Setup
This article extends [34] that deals with four different types of model architectures and how to incorporate the categories for training the word embeddings, in this work the Czech language has been chosen to test the model with the following setup: Model is initialized with categories that are uniformly distributed. During training the sentence from a training corpora, we add vectors of corresponding categories to actual context window. Motivation of our approach comes from Distributional hypothesis [10] that says: "words that occur in the same contexts tend to have similar meanings". If we are training with the categories, we believe they would behave with respect to the Distributional hypothesis.
6 Training
We previously tested our models on English Wikipedia dump from June 20162. The XML dump consist of 5,164,793 articles and 1,759,101,849 words. We firstly removed XML tags and kept only articles marked with respective id, further we removed articles with less than 100 words or less than 10 sentences. We removed categories that has less than 10 occurrences in between all articles. We have removed the articles without categories. The final corpus used for training consist of 1,554,079 articles. Czech Wikipedia dump comes from March 2017. Detailed statistics on these corpora are shown in Tables 1 and 2. For an evaluation, we experiment with word analogy and a variety of word similarity datasets.
— Word Similarity: These datasets are conducted to measure the semantic similarity between pair of words. For English, these include WordSim-353 [6], RG-65 [28], RW [19], LexSim-999 [12], and MC-28 [23]. For Czech, only two datasets are available and these include RG-65 [15] and WordSim-353 [5]. Both datasets consists of translated word pairs from English and re-annotated with Czech native speakers.
— Word Analogies: Follow observation that the word representation can capture different aspects of meaning, [21] introduced evaluation scheme based on word analogies. Scheme consists of questions, e.g. which word is related to man in the same sense as queen is related to king? The correct answer should be woman. Such a question can be answered with a simple equation: vec(king) - vec(queen) = vec(man) - vec(woman). We evaluate on English and Czech word analogy datasets, proposed by [21] and [33], respectively. The word-phrases were excluded from original datasets, resulting in 8869 semantic and 10,675 syntactic questions for English (19,544 in total), and 6018 semantic. 14,820 syntactic questions for Czech (20,838 in total).
Table 1 Training corpora statistics. English Wikipedia dump from June 2016
| English (dump statistics) | |
| Articles | 5,164,793 |
| Words | 1,759,101,849 |
| English (final clean statistics) | |
| Articles | 1,554,079 |
| Avg. words per article | 437 |
| Avg. number of categories per article | 4.69 |
| Category names vocabulary | 4,015,918 |
Table 2 Training corpora statistics. Czech Wikipedia dump from June 2016
| Czech (dump statistics) | |
| Articles | 575,262 |
| Words | 88,745,854 |
| Czech (final clean statistics) | |
| Articles | 480,006 |
| Avg. words per article | 308 |
| Avg. number of categories per article | 4.19 |
| Category names vocabulary | 261,565 |
6.1 Training Setup
We tokenize the corpus data. We use simple tokeniser based on regular expressions. After model is trained, we keep the most frequent words in a vocabulary (|W| = 300,000). Vector dimension for all our models is set to d = 300. We always run 10 training iterations. The window size is set 10 to the left and 10 to the right from the center word
fastText is trained on our Wikipedia dumps (see results in Table 3 and 4). LexVec is tested only for English, trained on Wikipedia 2015 + NewsCrawl3, has 7B tokens, vocabulary of 368,999 words and vectors of 300d. Both (fastText and LexVec) models use character n-grams of length 3-6 as subwords. For a comparison with much larger training data (only available for English), we downloaded GoogleNewslOOB4 model that is trained using Skipgram architecture on 100 billion words corpus and negative sampling, vocabulary size is 3,000,000 words.
Table 3 Word similarity and word analogy results on English
| Word similarity | Word analogy | |||||||
|---|---|---|---|---|---|---|---|---|
| Model | WS-353 | RG-65 | MC-28 | Simiex-999 | Sem. | Syn. | Total | |
| Baselines | fastText - SG 300d wiki | 46.12 | 76.31 | 73.26 | 26.78 | 68.77 | 67.94 | 68.27 |
| fastText - cbow 300d wiki | 44.64 | 73.64 | 69.67 | 38.77 | 69.32 | 81.42 | 76.58 | |
| SG GoogleNews 300d 100B | 68.49 | 76.00 | 80.00 | 46.54 | 78.16 | 76.49 | 77.08 | |
| CBOW 300d wiki | 57.94 | 68.69 | 71.70 | 33.17 | 73.63 | 67.55 | 69.98 | |
| SG 300d wiki | 64.73 | 78.27 | 82.12 | 33.68 | 83.64 | 66.87 | 73.57 | |
| LexVec 7B | 59.53 | 74.64 | 74.08 | 40.22 | 80.92 | 66.11 | 72.83 | |
| CBOW 300d + Cat | 63.20 | 78.16 | 78.11 | 40.32 | 77.31 | 68.68 | 72.13 | |
| SG 300d + Cat | 62.55 | 80.25 | 86.07 | 33.54 | 80.77 | 71.05 | 74.93 | |
Table 4 Word similarity and word analogy results on Czech
| Word similarity | Word analogy | ||||||
|---|---|---|---|---|---|---|---|
| Model | WS-353 | RG-65 | MC-28 | Sem. | Syn. | Total | |
| Baselines | fasttext - SG 300d wiki | 67.04 | 67.07 | 72.90 | 49.03 | 76.95 | 71.72 |
| fasttext - CBOW 300d wiki | 40.46 | 58.35 | 57.17 | 21.17 | 85.24 | 73.23 | |
| CBOW 300d wiki | 55.9 | 41.14 | 49.73 | 22.05 | 52.56 | 44.33 | |
| SG 300d wiki | 65.93 | 68.09 | 71.03 | 48.62 | 54.92 | 53.74 | |
| CBOW 300d + Cat | 54.31 | 47.03 | 49.31 | 42.00 | 62.54 | 58.69 | |
| SG 300d + Cat | 62 | 57.55 | 64.64 | 47.03 | 54.07 | 52.75 | |
7 Experimental Results and Discussion
We experiment with model defined in Section 5.1 and training Setup from Section 6.1.
As an evaluation measure for word similarity tasks we use Spearman correlation between system output and human annotations. For word analogy task we evaluate by accuracy of correctly returned answers. Results for English Wikipedia are shown in Table 3 and for Czech in Table 4. These detailed results allow for a precise evaluation and understanding of the behaviour of the method. First, it appears that, as we expected, it is more accurate to predict entities when categories are incorporated.
7.1 Discussion
Distributional word vector models capture some aspect of word co-occurrence statistics of the words in a language [17]. Therefore, these extended models produce semantically coherent representations, if we allow to see shared categories between semantically similar textual data, the improvements presented in Tables 3 and 4 is the evidence of the distributional hypothesis.
Our model on English also outperforms fastText architecture [1] that is a recent improvement of Word2Vec with sub-word information. With our adaptation, the CBOW architecture give similar performance as the Skipgram architecture trained on much larger data. On RG-65 word similarity test and semantic oriented analogy questions in Table 3 it gives better performance. We can see, that our model is powerful in semantics.
There is also significant performance gain on WS-353 similarity dataset and English language. Czech generally perform poorer, because of less amount of data to train and also due to the fact of the language properties. The Czech has free word order and higher morphological complexity that influences the quality of resulting word embeddings, that is also the reason why the sub-word information tends to give much better results. However, our method shows significant improvement in Semantics, where the performance with Czech language has improved twofold (see Table 4).
The individual improvements of word analogy tests with CBOW architecture are available in Table 5. These detailed results allow for a precise evaluation and analyse the behaviour of our model. In Czech language, we see the biggest gain in understanding of category "Jobs". This semantic category is specific to Czech language as it distinguishes between feminine and masculine form of profession. However, we do not see much difference in section "Nationalities" that also describes countries and masculine versus feminine form of its representatives. We think this might be caused of lack data from Wikipedia.
Table 5 Detailed word analogy results
| (a) CZ with CBOW and Categories | ||
| Type | Baseline | Cat |
| Antonyms (nouns) | 15.72 | 7.14 |
| Antonyms (adj.) | 19.84 | 46.20 |
| Antonyms (verbs) | 6.70 | 5.00 |
| State-cities | 35.80 | 50.57 |
| Family-relations | 31.82 | 50.64 |
| Nouns-plural | 69.44 | 75.93 |
| Jobs | 76.66 | 95.45 |
| Verb-past | 51.06 | 61.04 |
| Pronouns | 11.58 | 10.42 |
| Antonyms-acjectives | 71.43 | 81.82 |
| Nationalities | 20.40 | 21.31 |
|
(b) EN with CBOW and Categories | ||
| Type | Baseline | Cat. |
| Capital-common-countries | 84.98 | 88.34 |
| Capital-world | 81.78 | 87.69 |
| Currency | 5.56 | 5.56 |
| City-in-state | 62.55 | 65.22 |
| Family-relations | 92.11 | 90.94 |
| Adjective-to-adverb | 25.38 | 29.38 |
| Opposite | 41.67 | 37.08 |
| Comparative | 79.14 | 78.82 |
| Superlative | 59.74 | 64.50 |
| Present-participle | 61.95 | 65.89 |
| Nationality-adjective | 91.39 | 98.69 |
| Past-tense | 63.66 | 66.59 |
| Plural | 74.19 | 71.67 |
| Plural-verbs | 62.33 | 46.33 |
In Czech, we use mostly masculine form in articles when talking about people from different countries. In a section "Pronouns" that deals with analogy questions such as: "I, we" versus "you, they", we clearly cannot benefit from incorporating the categories. The biggest performance gain is as we expected in semantic oriented categories such as: Antonyms, State-cities and Family-relations. English gives slightly lower score in Family-relations section of analogy corpus.
However, as English semantic analogy questions are already hitting correlations above 80% and especially for this section already more than 90%, we believe that we are already hitting the maximal capabilities of machines and humans agreement. This is the reason why we bring up the comparison with highly inflected language. In [33] and [32] has been shown that there is a space for the performance improvement of current state-of-the-art word embedding models on languages from Slavic families. More information about individual section of Czech word analogy corpus is described in [33].
With Czech language, we investigated a drop in performance of the Skip-gram model. This fact might be caused of not enough data for the reverse logic of training the Skip-gram architecture.
8 Conclusion
8.1 Contributions
Our model with global information extracted from Wikipedia significantly outperform the baseline CBOW model. It provide similar performance compared with methods trained on much larger datasets.
We focused on currently widely used CBOW method and Czech language. As a source of global document (respective article) context we used Wikipedia that is available in 301 languages. Therefore,it can be adopted to any other language without necessity of manual data annotation. The model can help to the highly inflected languages such as Czech is, to create word embeddings that perform better with smaller corpora.
8.2 Future Work
We believe that using our method together with sub-word information can have even bigger impact on poorly resourced and highly inflected languages, such as Czech from Slavic family. Therefore, the future community work might lead to integrate our model to the latest architectures such as fastText or LexVec and improve the performance further from incorporating the sub-word information.
Also, we suggest to take a look into the other possibilities, how to extract useful information from Wikipedia and how to use it during training -such as references, notes, literature, external links, summary info (usually displayed on the right side of the screen) and others.
We provide the global information data and trained word vectors for research purposes5.

