











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1 Introduction
With the rapid growth of information on the Internet, it becomes extremely difficult for users to get what they really intend. Therefore, the creation of automatic summarization methods is considered as a very important task of natural language processing. This allows the user to quickly understand large amount of information. Automatic text summarization is a task to extract the most important part of the source text in a shorter way. It can be performed in two ways: extraction and abstraction. The extraction method selects sentences or phrases that have high marks of importance, and combines them into a new short text, without changing the selected units. In the method of abstraction, the main content is extracted from the source text and paraphrased using linguistic methods for semantic analysis and text interpretation.
In this work we experiment with extractive summarization method for the Kazakh language based on fuzzy logic. We collected and manually annotated our own dataset from the different Internet resources in the Kazakh language. Additionally, we conduct experiment on CNN/Daily Mail dataset [7], which is an open dataset for use in text summarization experiments in English. Our approach is based on the preprocessing of the sentences by applying morphological analysis and pronoun resolution techniques. Afterwards, we determine features to extract important sentences from the text. The architecture of the extractive text summarization approach based on fuzzy logic is shown in Figure 1.
This paper is organized as follows: Section II presents a brief review of the related works. Section III presents a methodology of proposed techniques for automatic text summarization. More precisely, it describes the following stages: text preprocessing, feature extraction and calculation, summarization using fuzzy logic. The dataset collection and experimental setup are described in Section IV. Experiment details and obtained results of the extractive text summarization task are also presented in this section. Summary of the performed experiments and areas of further research are given in Section V.
2 Related Work
This Section presents a brief review about automatic text summarization techniques. Many different techniques have been proposed for this task that utilizes a variety of different approaches. For a thorough review of works on text summarization the reader is advised to consult a very recent survey by [1].
We limit ourselves to a brief review of extractive text summarization, as our main aim is to score and select text units which have highest scores as summary. Shallow features [3], hidden markov models [8], discourse structure model [9], maximum marginal relevance [6], fuzzy logic [23] and swarm intelligence [4], conceptual graphs [5,18] approaches are proposed to deal with this task.
A lot of research has been done with respect to the Kazakh language [10-12,14,16,20], but there are a few researches regarding automatic text summarization. [19] implemented and compared different summarization techniques based on TextRank algorithm, namely: General TextRank, BM25, LongestCommonSubstring. They conducted experiments on corpora of news articles parsed from the web written in Russian and Kazakh. [22] performed an experiment to summarize articles from online news websites tengrinews.kz with extractive way.
3 Methodology
3.1 Text prepossessing
In this work we experiment with news articles of the most popular Kazakhstani news websites. To prepare our collected data set for the summarization task, we preprocess the text by deleting unnecessary indents, spaces, punctuation marks and other specific characters as described in [13,21]. Afterwards, we perform a segmentation similar to [2], which involves a breakdown of the text into sentences and tokenization of each sentence. The next steps in the preprocessing pipeline include such tasks as lemmatization, numerals identification, named entity recognition and finding pronouns. For these we compiled a morphologically dictionary and devised the empirical rules. Finally, we developed a rule-based algorithm for the pronoun resolution which for each found pronoun basically scans several previous sentences and calculates the most probable word or phrase it refers to. This is necessary to improve the quality of summarization, since pronouns such as "I", "he", "she", "they" usually are referred to "stop words" and, thus, removed from the text in the early stages. However, they indicate specific persons and carry certain significance. As a result of morphological and syntactic analysis, pronouns were replaced with the names of the persons they indicate. The pseudo-code of the algorithm used to pronoun replacement is illustrated in Figure 2. We remove stop words that are often found in the text, but do not represent a special meaning for determining the importance of the content. Deletion of affixes from a word by stemming concludes the text preprocessing.

3.2 Feature Extraction and Calculation
After preprocessing the text, it is necessary to extract features and calculate the functions of the sentence, the results of which are vectors of seven elements for each sentence. The elements of each vector take values in the interval [0, 1]. We consider the following features:
-
— Title feature (F1): It is defined as a ratio of the number of matches of the Title words (Tw) in the current sentence (S) to the number of words (w) of the Title (T) [24]:
-
— Sentence Length (F2): It is defined as a ratio of the number of words (w) in the current sentence (S) to the number of words in the longest sentence (LS) in the text [24]:
This function is necessary for filtering from the selection of short and incomplete sentences, such as an author of the article, date of the article, etc.
-
— Sentence position (F3): It is defined as a maximum of the next two relations [24]:
If the sentence is at the beginning of the text, then the first expression is the maximum, if the sentence is at the end of the text, then the maximum value will be taken by the second expression. This function is important when selecting, as more informative sentences are usually located at the beginning or at the end of the text.
-
— Thematic word (F4): It is defined as a ratio of the number of thematic words (Thw) in the current sentence (S) to the maximum number of thematic words (Thw) calculated on all sentences (S) of the text [24]:
Thematic words are the most frequently used words in the text. They are directly related to the main theme of the text. We chose the five most frequent words in the text as thematic ones.
-
— Term Weight (F5): It is defined as a ratio of the sum of the frequencies of term occurrences (TO) in a sentence (S) to the sum of the frequency of term occurrences in the text [24]:
To calculate the weight of a sentence, we find the frequency with which the term appears in the sentence and the frequency with which the same (current) term appears in the text
-
— Proper Noun (F6): It is defined as a ratio of the number of proper nouns (PN) in a sentence (S) to the length (L) of a sentence [24]:
Proper nouns found in the proposal carry a lot of information about personal facts. Therefore, the sentences with the most proper nouns are an important part of the content.
-
— Numerical Data (F7): It is defined as a ratio of the number of numerical data (ND) in the sentence (S) to the length (L) of the sentence [24]:
Typically, numerical data has specific important values for summarization. Therefore, numerical data in the text could not be skipped.
The importance of sentences regarding features is presented in Table 1.
Table 1 Importance of sentences (rule examples)
| Features | Low | Medium | High |
|---|---|---|---|
| topic/title | poor | average | verage decent or good |
| thematic word | poor | average | decent or good |
| term freq. | poor | average or mediocre | decent or good |
| proper noun | – | – | good |
| numerical data | – | – | not(poor) |
| sentence length | – | – | not(poor) |
| sentence position | – | – | not(poor) |
3.3 Fuzzy Logic System Design
Fuzzy logic system design includes the following concepts: fuzzy set, membership function, fuzzy logic operations, linguistic variables, linguistic terms, fuzzy logical values, fuzzy logic conclusion [26]. A typical fuzzy logic system consists of the following components:
The fuzzifier determines a correspondence between the clear numerical value of the input variable and the value of the membership function of the corresponding term of the linguistic variable. In our case, the linguistic variables are the seven functions defined by us above. They take meanings from a variety of words such as "poor", "mediocre", "average", "decent", "good". These words are called term-sets and take values in the interval [0, 1] (Figure 3). In short, fuzzification is the process of transition from a clear to a fuzzy representation [26].
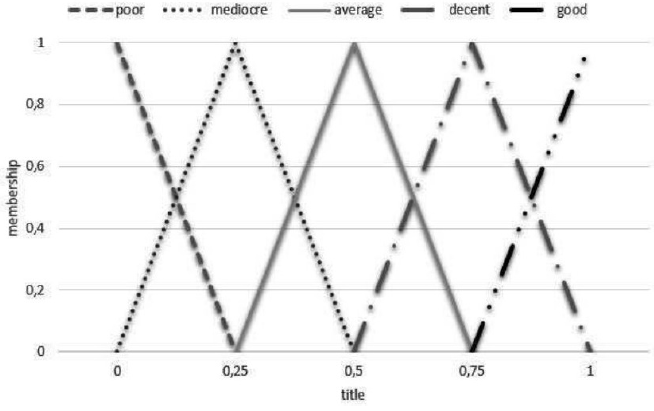
The fuzzifier depends on the membership function forthe corresponding linguistic terms. One of the main problems of using fuzzy logic is a choice of the membership functions of the linguistic variables. The main types of the membership functions are triangular, trapezoidal, piecewise linear, Gaussian, sigmoid, and otherfunctions. The choice of the membership function of a particular variable is a poorlyformalized problem, the solution of which is based on intuition and experience [26].
For our task, we have prepared a more appropriate triangular membership function used to specify uncertainties of the type: "approximately equal", "average value", "located in the interval", "similar to the object", "similar to the object", etc.
The quality of fuzzy inference depends on the correct construction of "IF-THEN" rules. We obtained rules for a fuzzy knowledge base on the basis of analysis of manually written summaries. Since all the membership functions of linguistic variables are known to us, and the rules we need are defined, we proceed to the aggregation process. Aggregation is a procedure for determining the truth degree of conditions according to each rules of the fuzzy inference system. The values of the membership functions of the linguistic variable terms obtained at the stage of fuzzification are used. If the condition of a fuzzy production rule is a simple fuzzy statement, then the degree of its truth corresponds to the value of the membership function of the corresponding term of the linguistic variable.
If a condition is a compound statement, then the truth degree of the complex statement is determined on the basis of the known truth values of its elementary statements using the fuzzy logic operations introduced earlier [26]. After the logical inference, we obtain fuzzy values by accessing the fuzzy knowledge base. Also we obtain clear values for the output using the defuzzification of the fuzzy values of the linguistic variables (Figure 1).
Defuzzification is the procedure for converting a fuzzy set to a clear number. In the theory of fuzzy sets, the defuzzification is similar to finding the position characteristics (expectation, mode, median) of random variables in probability theory. The simplest way to perform the defuzzification is to select a clear number corresponding to the maximum membership function [26].
For software implementation of text summarization based on fuzzy logic, we used the python language and the skfuzzy package [25]. We constructed the membership function for each function value from five fuzzy sets: poor, mediocre, average, decent, good. Example of the membership function of the header function (Figure 3)
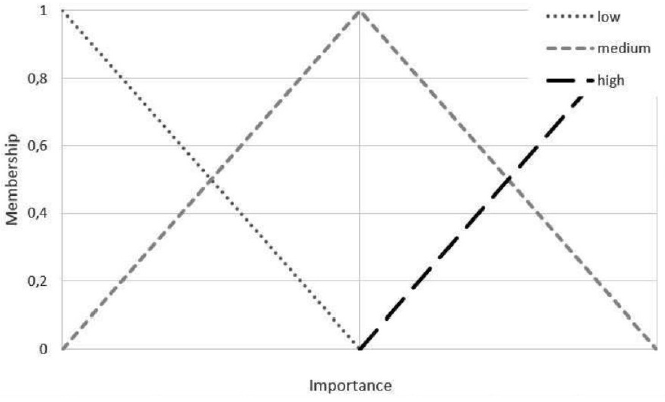
The last step of the fuzzy inference is defuzzification, i.e. output membership function, which we have broken into three: low, medium, high (Figure 4). The pseudo-code of the algorithm used to pronoun replacement is illustrated in Figure 5.

4 Experimental Setup and Results
4.1 Data Set
The data set for the given task was collected from the news articles of the most popular Kazakhstani online news websites, namely kt.kz, bnews.kz, qazaquni.kz and qazaqtimes.com. The articles cover a wide range of topics and hence represent styles with high variety. Human annotators were asked to write an extractive summary of the article with respect to the style it was written in. Moreover, since we utilized the ROUGE package evaluation metric [15] which uses the reference summary or ideal summary, the extractive summary pair has to be verified by at least two annotators. The professional activity of each annotator also has to be taken into account as well. We also assess the performance of our approach on the selected part of CNN/Daily Mail dataset, which is a popular and free dataset for use in text summarization experiments. This dataset consists of news articles paired with multi-sentence summaries. For the pronoun resolution we used Stanford CoreNLP toolkit [17].
The average number of sentences in articles and the average number of sentences in summaries for both dataset are presented in Table 2.
4.2 Results
In this section, we present our experimental results for the automatic text summarization. We compare results obtained through applying our approach on both the Kazakh news dataset and CNN/Daily Mail dataset.
ROUGE metrics were used for a preliminary assessment of the work quality. More precisely, ROUGE-L considers sentence level structure similarity and determines the longest co-occurring in sequence n-grams in automatic way. ROUGE-1 shows the overlap of unigram between the system and reference summaries, whereas ROUGE-2 indicates for bigrams [15].
Table 3 lists the results of the experiments on text summarization for the Kazakh news dataset. As it can be seen the proposed pronoun resolution achieves better result rather than without pronoun resolution. The significant increase is indicated for Rouge-L (f-score): from 0.35 to 0.40. Rouge-1 (f-score) and Rouge-2 (f-score) scores are rised to 0.02 and 0.03, respectively. Moreover, we applied our method to CNN/Daily Mail dataset. Rouge-1 (f-score) and Rouge-L (f-score) scores show the same result, which are 0.38, whereas Rouge-2 (f-score) shows slightly worse result. An example of the automatic text summarization for the Kazakh language is shown in Table 5.
Table 3 Rouge scores for the Kazakh news dataset
| Rouge | metrics | Without pronoun resolution |
With pronoun resolution |
|---|---|---|---|
| Rouge-1 | precision | 0.38 | 0.39 |
| Recall | 0.39 | 0.44 | |
| f-score | 0.36 | 0.38 | |
| Rouge-2 | precision | 0.32 | 0.34 |
| Recall | 0.33 | 0.37 | |
| f-score | 0.31 | 0.34 | |
| Rouge-L | precision | 0.38 | 0.39 |
| Recall | 0.40 | 0.44 | |
| f-score | 0.35 | 0.40 |
Table 4 Rouge scores for the CNN /Daily Mail dataset with pronoun resolution
| Rouge | metrics | CNN/Daily Mail dataset |
|---|---|---|
| Rouge-1 | precision | 0.35 |
| Recall | 0.41 | |
| f-score | 0.38 | |
| Rouge-2 | precision | 0.33 |
| Recall | 0.36 | |
| f-score | 0.34 | |
| Rouge-L | precision | 0.32 |
| Recall | 0.4 | |
| f-score | 0.38 |
Table 5 Example of the automatic text summarization
| Manual summarization |
Automatic summarization |
Sentence weight (importance indicator) |
Feature vectors |
|---|---|---|---|

|

|
0.76666 - high | [0.31, 0.62, 0.5, 1.0, 1.0, 0.25, 0.25] |

|
0.766127 - high | [0.0, 0.77, 0.25, 0.0, 0.62, 0.1, 0.2] | |

|
0.766127 - high | [0.0, 0.46, 0.16, 0.33, 0.45, 0.17, 0.17] |
5 Conclusion
The research in the field of computational linguistics for the Kazakh language is expanding rapidly. Therefore, the results of the work will be very popular for a quick public perception of the summary content of a large flow of information. The algorithm of the extractive method of abstracting using fuzzy logic has proved to be effective for the tasks of automatic summarizing of news articles dataset in the Kazakh language. In this work we presented an extractive summarization method on the basis of fuzzy logic. Our approach is advanced by applying morphological analysis and pronoun resolution techniques. The experiments conducted on Kazakh news and CNN/ Daily Mail dataset show perspective results. Nevertheless, the algorithm requires improvements and the inclusion of additional methods in the algorithm, which will allow not only to extract important content, but also to paraphrase in order to more closely correspond to the manual abstract. As a future work, we aim to increase our dataset. Moreover, we want to convert the extracted summaries to abstractive one using neural network techniques.

