











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1 Introduction
Recurrent neural networks (RNNs) were already conceived in the 1980s. But these types of neural networks have been very difficult to train due to their computing requirements and until the arrival of the advances of recent years, their use by the industry has become more accessible and popular [2, 3, 4, 5, 10].
A recurrent neural network (RNN) is one that can be connected to any other and its recurring connection is variable. Partially recurring networks are those that your recurring connection fixed [1, 2, 9, 11, 14, 17].
Recurrent Neural Networks are dynamic systems mapping input sequences into output sequences [19, 21, 22, 23].
The calculation of an input, in a step, depends on the previous step and in some cases the future step [34, 35, 40, 44]. RNN are capable of performing a wide variety of computational tasks including sequence processing, one-path continuation, nonlinear prediction, and dynamical systems modeling [38, 47, 49, 50, 52].
The purpose of carrying out a time series analysis of this type is to extract the regularities that are observed in the past behavior of a variable that is, obtain the mechanism that generates it, and know its behavior based on it over time.
This is under the assumption that the structural conditions that make up the phenomenon under study remain constant, to predict future behavior by reducing uncertainty in decision-making [6, 7, 8, 12, 29].
The essence of this work, is propose a new algorithm to design time prediction systems, where recurrent neural networks are applied to analyze the data, also type-1 and interval type-2 fuzzy inference systems to improve the prediction of time series.
For this, we apply a search algorithm to obtain the best architecture of the recurrent neural network, and in this way test the efficiency of the proposed hybrid method [6, 7, 8, 12, 29].
Genetic algorithms have been applied to various areas, such as forecasting classification, image segmentation routes for robots stand out, etc.
Their hybridation with other techniques improves the results of energy price predictions, raw materials and agricultural products, that is why we apply them to this approach, since they are tools that help use predict a time series and find good solutions, we have previously done work with this metaheuristic and they have given us good results, for this reason we apply it to network optimization neural ensemble for time series.
This work describes the creation of the ensemble recurrent neural network (ERNN), this model is applied to the prediction of the time series [28, 31, 36, 39, 41], the architecture is optimized with genetic algorithms, (GA) [16, 26, 27, 46].
The results of the integration of the Recurrent Neural Network are integrated with type-1 and interval type-2 fuzzy systems (IT2FS), [30, 32, 33, 43, 48]. The essence of this paper is the proposed architecture of the ERNN and the optimization is done using Genetic Algorithms, (GA), applied to the prediction of time series.
Two systems are proposed fuzzy type-1 and T2FS, to integrate the responses of the (ERNN), the optimization consists in the number of hidden layer (NL), their number of neurons (NN) and the number of modules (NM),) in the ERNN, the we integrate responses ERNN, with type-1 and IT2FS and in this way we achieve prediction. Mamdani fuzzy inference system (FIS) has five inputs which are Pred1, Pred2, Pred3, Pred4, and Pred5 and one output is called prediction.
The number of inputs of the fuzzy system (FS) is according to the outputs of ERNN. Mamdani fuzzy inference system (FIS) is created, this FIS five inputs which are Pred1, Pred2, Pred3, Pred4, and Pred5, (with a range) the range 0 to 1.4, the outputs is called prediction, the range goes from 0 to 1.4 and is granulated into two MFs "Low", "High", as linguistic variables.
This document is constituted by: Section 2 shows the database, in Section 3 the problem to be solved of the proposed model, Section 4 shows results of the proposed model, and Section 5 Conclusions.
2 Related Word
As related work, we can find a comparison was made using recurrent networks for the Puget Electric Demand time series, a learning algorithm was implemented for recurrent neural networks and tests were performed with outliers of data and in this way compare the capacity of loses, as well as the advantages of feedforward neural networks for time series are shown [18].
In [45] a recurrent neural network was developed for prognostic problems; the time series of long memory patterns was used and tests were also carried out with the integrated fractional recurrent neural network (FIRNN) algorithm.
In another study it was shown the performance of the cooperative neuro-evolutionary methods, in this case Mackey-Glass, Lorenz and Sunspot time series, and also two training methods Elman recurrent neural networks [37].
In another study, the prediction of time series was carried out, and the recurrent neural networks were used to make predictions. In this way the effectiveness of recurrent networks for the forecasting of chaotic time series was demonstrated [51].
In the study presented in [20], Recurrent Neural Networks (RNNs), are used to model the seasonality of a series in dataset possess homogeneous seasonal patterns.
Comparisons with the autoregressive integrated (ARIMA) and against exponential smoothing (ETS), demonstrate that RNN models are not best solutions, but they are competitive.
In [57], advanced neural networks were used for short term prediction.
Also, the exponential smoothed (ES) model for the time series are used, and this allows the equations to capture seasonality and the level more effectively, these networks allow trends non-linear and cross-learning, data is exploited hierarchically and local and global components are used to extract and combine data from or from a data series in order to obtain a good prediction.
This section shows the data set that was used to build the proposed model, in this case the Mackey-Glass time series are used.
2.1 Dataset Proposed
In this case we work the Mackey Glass time series with eight hundred data, we used 70% and 30% data for the training and testing, respectively. The following equation represents the Mackey-Glass time series:
where:
The plot of the Mackey Glass for the values mentioned in the equation is presented in Fig. 1. [25, 26].

In Fig. 2, the graph of the Mexican Stock Exchange data [42] is presented. In this case, we use 800 data that correspond to period from 01/04/2016 to 31/12/2019. We used 70% of the data for the RNN trainings and 30% to test the RNN.

Fig. 3 presents the graph of the Dow Jones data [16], where we are using 800 data that correspond to period from 07/01/2017 to 09/05/2019. We used 70% of the data for the RNN trainings and 30% to test the RNN.

In Fig. 4 the graph of the data US Dollar/MX Peso [13] is illustrated, where we use 800 data that correspond to the period from 07/01/2016 to 09/05/2019. We used 70% of the RNN training and 30% to test the RNN.

We trained the ensemble recurrent neural network with 500 data points, and we use the Bayesian regularization backpropagation method (trainbr) with a set of 300 points for testing, this is for each of the previously mentioned times series.
3 Problem Statement and the Proposed Method
In this Section, it is explained how the ERNN optimization model was created, its integration with type-1 and IT2FS, and we also describe every detail of the technique used for the optimization of the ERNN, as well as type-1 and IT2FS for the prediction of the time series.
3.1 Proposed General Scheme
The first part is to obtain the dataset of the time series, the second part it is determining the number of modules ERNN with the genetic algorithm, and the third part would be to integrate with type-1 and T2FS type-2 the responses of the ERNN to finally achieve time series prediction, as can be observed in Fig. 5.

3.1.1 Creation of the Recurrent Neural Network (RNN)
Recurrent neural networks (RNNs) have all the characteristics and the same operation of simple neural networks, with the addition of inputs that reflect the state of the previous iteration. They are a type of network whose connections form a closed circle with a loop, where the signal is forwarded back to the network, that is, the neural network’s own outputs become inputs for later instants. This feature endows them with memory and makes them suitable for time series modeling. The layer that contains the delay units is also called the context layer, as shown (as can be illustrated) in Fig. 6:

The recurrent neural network is made up of several units of a fixed activation function, one for each time step, each unit has a state and it is called the hidden state of the unit and it means that the network has past knowledge and a certain time step. This hidden state is updated and signifies the change in the network's knowledge about the past:
where
The new hidden state is calculated at each time step, and recurrence is used as above and the new hidden state is used to generate a new state, and so on.
Where the input stream from the previous layer, the weights of the matrix, and bias already seen in the previous layers. RNNs extend this function with a recurring connection in time, where the weight matrix operates on the state of the neural network at the previous time instant. Now, in the training phase through Backpropagation, the weights of this matrix are also updated.
3.1.2 Description of the GA for RNN Optimizations
The parameters of the recurrent neural network that are optimized with the GA are:
The following equation represents the objective function that (that is implemented in GA) we used with a genetic algorithm to minimize to prediction error of the time series:
where
Fig. 7 presents the structure of the GA chromosome.
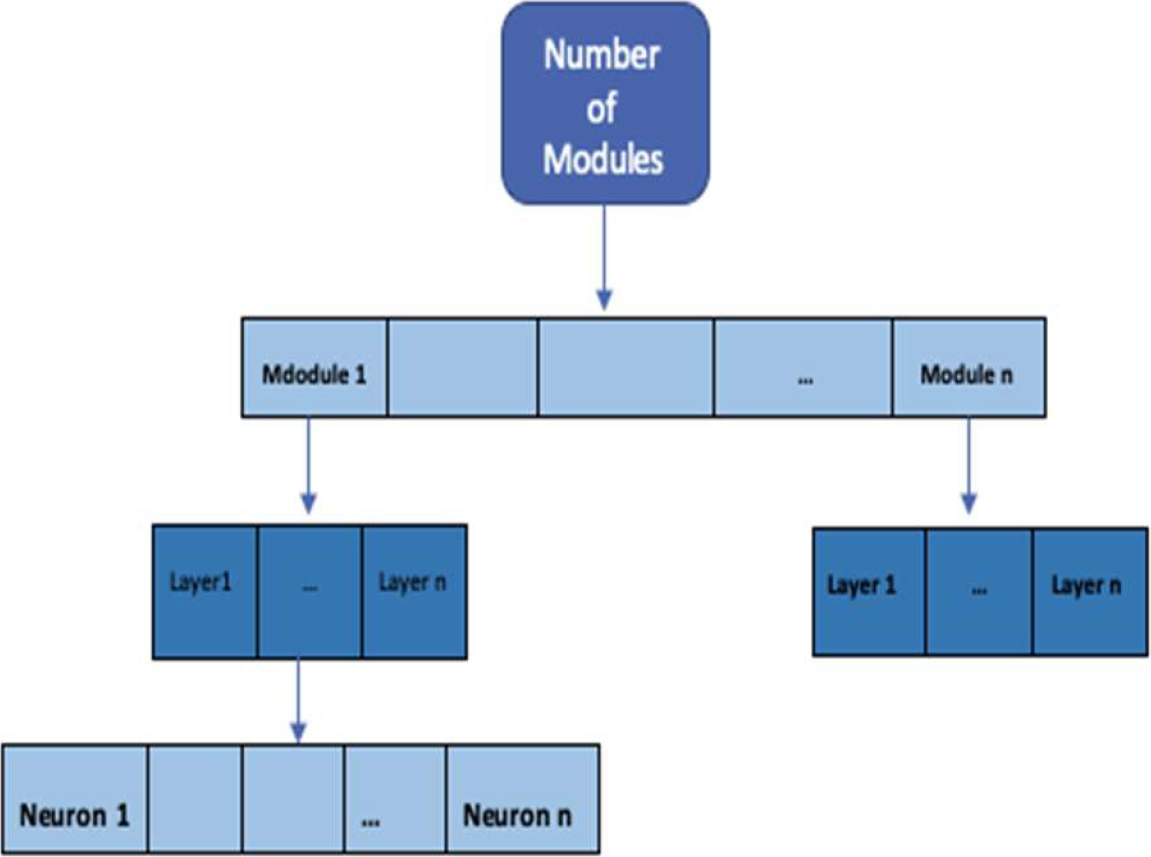
The main goal to optimize the ERNN architecture, with a GA is to obtain the best prediction error, which seeks to optimize NM, NL, and NN of the ERNN. Table 1 shows the values of the search space of the GA.
Table 1 Table of values for search space
| Parameters of RNN | Minimum | Maximum |
| Modules | 1 | 5 |
| Hidden Layers | 1 | 3 |
| Neurons for each hidden Layer | 1 | 30 |
In Table 2, the values of the parameters used for each optimization algorithm are presented. The mutation value is variable and shown in Table 2.
3.1.3. Description of the type-1 and IT2FS
The next step is the description of the type-1 fuzzy system and IT2FS. The following equation shows how the total results of the FS are calculated:
where
Fig. 8 shows a Mamdani fuzzy inference system (FIS) that is created. This FIS has five inputs, which are Pred1, Pred2, Pred3, Pred4, and Pred5, the range 0 to 1.4, the output is called prediction and the range goes from 0 to 1.4 and is granulated into two MFs "Low", "High", as linguistic values.

The Fuzzy system rules are as follows (as shown in Figure 9), since the fuzzy system has 5 input variables with two MFs and one output with two MFs, therefore the possible number of rules is 32.

4 Experimentation Results
This part presents the experiments of the optimization of the ERNN with the GA, as well the integration type-1 and IT2FS.
In addition, we present graphs of real data against predicted and results of the prediction for each of the experiments of Mackey Glass benchmark, Mexican Stock Exchange, Dow Jones, and Exchange Rate of US Dollar/Mexican Pesos time series. The following table shows the results of the genetic algorithm, where the best architecture of the ERNN is shown in row number 7 of Table 3 for the Mackey-Glass time series.
Table 3 Genetic algorithm results for the RNN of MG
| Evolutions | Gen. | Ind. | Pm | Pc | Num. Modules | Num. Layers | Num. Neurons | Duration | Prediction Error |
| 1 | 100 | 100 | 0.07 | 0.6 | 3 | 2 | 22,23 18,19 17,16 |
05:10:11 | 0.0017568 |
| 2 | 100 | 100 | 0.05 | 0.7 | 5 | 2 | 18,22 23,24 25,26 20,21 18,20 |
06:22:16 | 0.0019567 |
| 3 | 100 | 100 | 0.07 | 0.5 | 4 | 2 | 25,26 20,22 24,25 21,22 |
07:24:22 | 0.0020174 |
| 4 | 100 | 100 | 0.03 | 0.4 | 5 | 2 | 18,22 23,24 25,26 20,21 18,20 |
07:36:27 | 0.0016789 |
| 5 | 100 | 100 | 0.09 | 0.9 | 3 | 2 | 18,22 21,22 15,16 |
06:15:16 | 0.0017890 |
| 6 | 100 | 100 | 0.05 | 0.5 | 5 | 2 | 19,20 23,24 25,26 |
09:35:23 | 0.0020191 |
| 7 | 100 | 100 | 0.09 | 0.9 | 3 | 2 | 24,25 23,22 20,21 |
0:06:17 | 0.0015678 |
| 8 | 100 | 100 | 0.09 | 1 | 5 | 2 | 19,18 21,22 27,28 24,24 21,22 | 06:12:11 | 0.0018904 |
| 9 | 100 | 100 | 0.04 | 0.7 | 4 | 2 | 19,20 21,22 25,25 18,22 |
06:13:34 | 0.0855 |
| 10 | 100 | 100 | 0.03 | 0.7 | 5 | 3 | 20,19,22 18,19,19 22,24,27 21,19,20 26,25,26 |
08:20:19 | 0.0016311 |
Table 4 illustrates the results of the type-1 FS integration for the optimized ERNN, where the obtained result is of experiment number 8, with a prediction error: 0.1667. Figure 9 represents the plot of the real data against predicted data for the type-1 fuzzy system for the Mackey-Glass time series. Table 5 and Figure 10 represent the prediction of the time series using the IT2FS for the Mackey-Glass time series, respectively. Table 6 shows the results of the genetic algorithm, where the best architecture of the ERNN is shown in row number 2 of Table 6 for the Mexican Stock Exchange time series.
Table 4 Results of type-1 FS for MG
| Test |
Prediction Error with Type-1 Fuzzy Integration |
| 1 | 0.1731 |
| 2 | 0.2012 |
| 3 | 0.1965 |
| 4 | 0.2034 |
| 5 | 0.1886 |
| 6 | 0.2898 |
| 7 | 0.2234 |
| 8 | 0.1667 |
| 9 | 0.1945 |
| 10 | 0.2225 |

Table 5 Results of the IT2FS of MG
| Test | Prediction Error 0.3 Uncertainty | Prediction Error 0.4 Uncertainty | Prediction Error 0.5 Uncertainty |
| 1 | 0.3122 | 0.2815 | 0.2512 |
| 2 | 0.3321 | 0.3017 | 0.2906 |
| 3 | 0.4256 | 0.3792 | 0.4326 |
| 4 | 0.3689 | 0.3512 | 0.3891 |
| 5 | 0.5995 | 0.5725 | 0.5519 |
| 6 | 0.4912 | 0.4315 | 0.4654 |
| 7 | 0.5276 | 0.5045 | 0.5618 |
| 8 | 0.3044 | 0.3426 | 0.3725 |
| 9 | 0.5122 | 0.5389 | 0.5554 |
| 10 | 0.5572 | 0.5437 | 0.5215 |
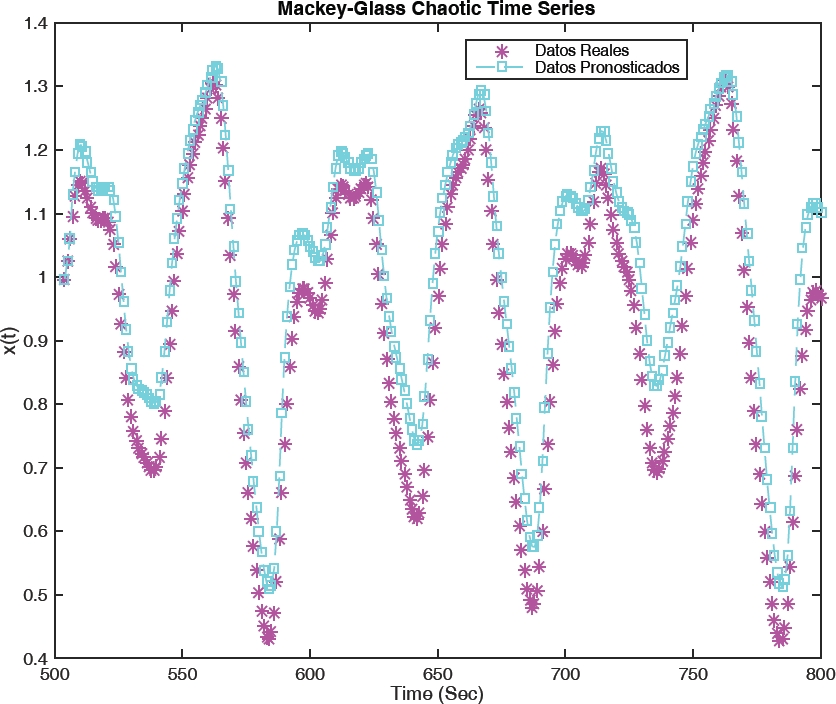
Table 6 Genetic algorithm results for the RNN of MSE
| Evolutions | Gen. | Ind. | Pm | Pc | Num. Modules | Num. Layers | Num. Neurons | Duration | Prediction Error |
| 1 | 100 | 100 | 0.07 | 0.6 | 3 | 3 | 28,6,24 28,6,24 14,30,26 |
01:27:18 | 0.0048872 |
| 2 | 100 | 100 | 0.05 | 0.7 | 2 | 2 | 28,12 28,12 |
01:16:49 | 0.0047646 |
| 3 | 100 | 100 | 0.07 | 0.5 | 2 | 1 | 15 15 |
00:56:20 | 0.005684 |
| 4 | 100 | 100 | 0.03 | 0.4 | 2 | 2 | 18,2 18,2 |
01:24:27 | 0.00488 |
| 5 | 100 | 100 | 0.09 | 0.9 | 2 | 2 | 1,12 1,12 |
01:05:01 | 0.004078 |
| 6 | 100 | 100 | 0.05 | 0.5 | 2 | 2 | 22,21 11,12 |
01:00:19 | 0.004108 |
| 7 | 100 | 100 | 0.09 | 0.9 | 2 | 2 | 1,3 1,3 |
01:23:08 | 0.0053897 |
| 8 | 100 | 100 | 0.09 | 1 | 5 | 5 | 1 1 1 7 8 |
01:37:40 | 0.0021431 |
| 9 | 100 | 100 | 0.04 | 0.7 | 2 | 1 | 30 30 |
01:44:21 | 0.004596 |
| 10 | 100 | 100 | 0.03 | 0.7 | 2 | 3 | 1,3,28 1,3,28 |
02:00:22 | 0.0056895 |
Table 7 shows the results of the type-1 FS integration for the optimized ERNN, where the result obtained is of experiment number 4, with a prediction error: 0.3270. Figure 11 represents the plot of the real data against predicted data for the type-1 fuzzy system for the Mexican Stock Exchange time series.
Table 7 Results of type-1 FS for MSE
| Test | Prediction Error With Type-1 Fuzzy Integration |
| 1 | 0.3272 |
| 2 | 0.3275 |
| 3 | 0.3271 |
| 4 | 0.3270 |
| 5 | 0.3271 |
| 6 | 0.3272 |
| 7 | 0.3271 |
| 8 | 0.3280 |
| 9 | 0.3271 |
| 10 | 0.3273 |

Table 8 and Figure 12 illustrates the prediction of the time series using the IT2FS for the Mexican Stock Exchange time series.
Table 8 Results of type-2 FS of MS
| Test | Prediction Error 0.3 Uncertainty | Prediction Error 0.4 Uncertainty | Prediction Error 0.5 Uncertainty |
| 1 | 0.3122 | 0.2815 | 0.2512 |
| 2 | 0.3321 | 0.3017 | 0.2906 |
| 3 | 0.4256 | 0.3792 | 0.4326 |
| 4 | 0.3689 | 0.3512 | 0.3891 |
| 5 | 0.5995 | 0.5725 | 0.5519 |
| 6 | 0.4912 | 0.4315 | 0.4654 |
| 7 | 0.5276 | 0.5045 | 0.5618 |
| 8 | 0.3044 | 0.3426 | 0.3725 |
| 9 | 0.5122 | 0.5389 | 0.5554 |
| 10 | 0.5572 | 0.5437 | 0.5215 |
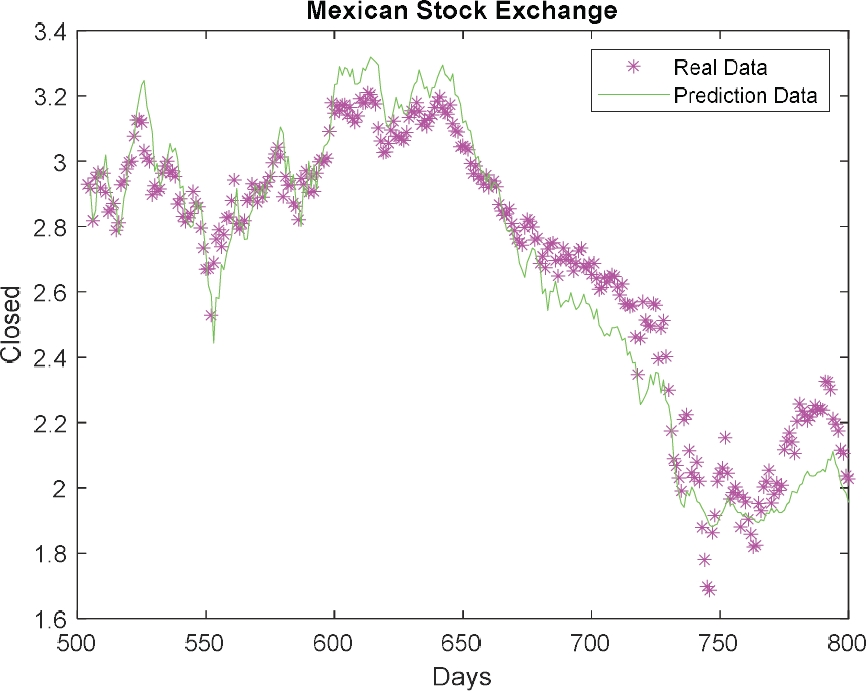
Table 9 shows the results of the genetic algorithm, where the best architecture of the ERNN is shown in row number 2 of Table 9 for the Dow Jones time series.
Table 9 Genetic algorithm results for the RNN for the DJ
| Evolutions | Gen. | Ind. | Pm | Pc | Num. Modules | Num. Layers | Num. Neurons | Duration | Prediction Error |
| 1 | 100 | 100 | 0.07 | 0.6 | 5 | 3 | 24,30,9 13,26,15 17,22,25 13,25,30 1,21,30 |
18:07:07 | 0.0023472 |
| 2 | 100 | 100 | 0.05 | 0.7 | 5 | 5 | 5,8,1 12,16,16 9,7,12 6,20,15 1,2,7 |
16:25:18 | 0.0018525 |
| 3 | 100 | 100 | 0.07 | 0.5 | 5 | 3 | 22,2,1 14,24,25 9,12,23 8,21,10 1,17,22 |
17:08:49 | 0.028711 |
| 4 | 100 | 100 | 0.03 | 0.4 | 5 | 2 | 6,29 6,2 5,17 8,9 2,6 |
19:09:55 | 0.0022167 |
| 5 | 100 | 100 | 0.09 | 0.9 | 5 | 3 | 15,16,1 5,10,4 3,16,4 6,30,6 7,30,30 |
18:05:13 | 0.0021315 |
| 6 | 100 | 100 | 0.05 | 0.5 | 5 | 3 | 30,11,4 30,18,17 13,9,29 7,21,5 2,1,14 |
17:20:12 | 0.0026022 |
| 7 | 100 | 100 | 0.09 | 0.9 | 5 | 3 | 8,1,15 6,22,11 4,8,22 6,30,27 1,10,2 |
17:22:17 | 0.0025405 |
| 8 | 100 | 100 | 0.09 | 1 | 5 | 3 | 7,8,1 6,30,6 15,30,8 12,30.27,3 3,30,30 |
18:23:24 | 0.0022419 |
| 9 | 100 | 100 | 0.04 | 0.7 | 5 | 3 | 9,9,26 9,15,22 13,28,8 1,19,4 2,10,24 |
19:20:14 | 0.002269 |
| 10 | 100 | 100 | 0.03 | 0.7 | 4 | 3 | 16,16,1 4,15,4 6,27,7 10,30,20 17,22,29 |
19:02:31 | 0.002593 |
Table 10 shows the results of the integration type-1 FS for the optimized ERNN, where the result obtained is of experiment number 5, with a prediction error: 0.10567 and Figure 13 represents the plot of real data against predicted data for the type-1 fuzzy system.
Table 10 Results of type-1 FS of DJ
| Test |
Prediction Error with Type-1 Fuzzy Integration |
| 1 | 0.11343 |
| 2 | 0.12376 |
| 3 | 0.26920 |
| 4 | 0.14675 |
| 5 | 0.10567 |
| 6 | 0.22561 |
| 7 | 0.17888 |
| 8 | 0.18886 |
| 9 | 0.26922 |
| 10 |

Table 11 and Figure 14 represent the prediction of the time series using the IT2FS for the Dow Jones time series.
Table 11 Results of type-2 FS of DJ
| Test | Prediction Error 0.3 Uncertainty | Prediction Error 0.4 Uncertainty | Prediction Error 0.5 Uncertainty |
| 1 | 0.0188 | 0.0188 | 0.0172 |
| 2 | 0.0117 | 0.0117 | 0.0145 |
| 3 | 0.0156 | 0.0156 | 0.0164 |
| 4 | 0.0138 | 0.0176 | 0.0137 |
| 5 | 0.0178 | 0.018 | 0.0185 |
| 6 | 0.0217 | 0.0224 | 0.0243 |
| 7 | 0.0169 | 0.017 | 0.0152 |
| 8 | 0.0163 | 0.0163 | 0.0165 |
| 9 | 0.0156 | 0.0154 | 0.0151 |
| 10 | 0.0208 | 0.0208 | 0.0218 |

Table 12 shows the results of the genetic algorithm, where the best architecture of the ERNN is shown in row number 4 of Table 12, for the US/Dollar Mexican Pesos time series.
Table 12 Genetic algorithm results for the RNN of Dollar
| Evolutions | Gen. | Ind. | Pm | Pc | Num. Modules | Num. Layers | Num. Neurons | Duration | Prediction Error |
| 1 | 100 | 100 | 0.07 | 0.6 | 5 | 1 | 1 1 9 6 1 |
02:01:34 | 0.00213 |
| 2 | 100 | 100 | 0.05 | 0.7 | 5 | 3 | 11,26,30 4,23,14 1,2,13 12,2,6 1,16,30 |
07:35:18 | 0.0018864 |
| 3 | 100 | 100 | 0.07 | 0.5 | 5 | 1 | 1 1 3 11 1 |
02:21:04 | 0.0029528 |
| 4 | 100 | 100 | 0.03 | 0.4 | 5 | 1 | 3 6 2 19 3 |
02:09:55 | 0.0018685 |
| 5 | 100 | 100 | 0.09 | 0.9 | 5 | 1 | 1 1 1 6 1 |
02:12:04 | 0.0030438 |
| 6 | 100 | 100 | 0.05 | 0.5 | 5 | 5 | 5,25,24 7,24,9 1,29,22 4,25,30 1,23,13 |
02:53:46 | 0.0020584 |
| 7 | 100 | 100 | 0.09 | 0.8 | 5 | 1 | 2 13 4 6 2 |
01:54:24 | 0.0021801 |
| 8 | 100 | 100 | 0.09 | 1 | 5 | 1 | 1 1 1 7 1 |
01:34:18 | 0.0021431 |
| 9 | 100 | 100 | 0.04 | 0.7 | 5 | 1 | 1 1 1 2 1 |
01:38:38 | 0.0022053 |
| 10 | 100 | 100 | 0.03 | 0.7 | 5 | 1 | 2 12 5 8 1 |
01:36:38 | 0.0025446 |
Table 13 illustrates the results of the type-1 FS integration for the optimized ERNN, where the result obtained is of experiment number 4, with a prediction error: 0.113072 and Figure 15 represents the plot of real data against predicted data for the type-1 fuzzy system, for the US/Dollar Mexican Pesos time series.
Table 13 Results of type-1 FS of Dollar data
| Test |
Prediction Error with Type-1 Fuzzy Integration |
| 1 | 0.114981 |
| 2 | 0.11307 |
| 3 | 0.115 |
| 4 | 0.113072 |
| 5 | 0.114809 |
| 6 | 0.11319 |
| 7 | 0.119767 |
| 8 | 0.115691 |
| 9 | 0.113076 |
| 10 | 0.114352 |

Table 14 and Figure 16 illustrate the prediction of the time series using the IT2FS for the US/Dollar Mexican Pesos time series.
Table 14 Results of type-2 FS of Dollar data
| Test | Prediction Error 0.3 Uncertainty | Prediction Error 0.4 Uncertainty | Prediction Error 0.5 Uncertainty |
| 1 | 0.2341 | 0.2215 | 0.3972 |
| 2 | 0.2217 | 0.2056 | 0.3779 |
| 3 | 0.2118 | 0.2019 | 0.3888 |
| 4 | 0.1979 | 0.1845 | 0.3985 |
| 5 | 0.1722 | 0.1944 | 0.3612 |
| 6 | 0.1922 | 0.2251 | 0.3758 |
| 7 | 0.2012 | 0.2252 | 0.3763 |
| 8 | 0.2212 | 0.2019 | 0.3794 |
| 9 | 0.2132 | 0.2313 | 0.3590 |
| 10 | 0.2055 | 0.1903 | 0.3674 |

4.1 Comparison of Results
Comparisons were made with the paper called: “A New Method for Type-2 Fuzzy Integration in Ensemble Neural Networks Based on Genetic Algorithms”, where the same data from the series of the Mackey-Glass were used.
In this case, we obtained that recurrent neural networks are better for predicting data from this series since there is a significant difference in the results, as they are better with the recurrent neural than with ensemble neural network.
Therefore, we use a significance of 90% and according to the results obtained and we can say that there is significant improvement with the ensemble neural network, as is summarized in Table 15. Comparisons were also made with the paper called: “Particle swarm optimization of ensemble neural networks with fuzzy aggregation for time series prediction of the Mexican Stock Exchange”, where the same data from the series of the Mexican stock exchange were used.
Table 15 Results of comparison of the Mackey-Glass
| Time Series | N(RNN) | N(ENN) | Value(T) | Value(P) |
| Dow Jones | 30 | 30 | -0.5091 | 0.0694 |
We obtained that recurrent neural network is better for predicting data from this series since there is a significant difference in the results are better the recurrent neural that with ensemble neural network. Therefore, we use a significance of 99% and according to the results obtained we can say that there is significant improvement with the ensemble neural network, as summarizes in Table 16.
Table 16 Results of comparison of the Mexican Stock Exchange
| Time Series | N(RNN) | N(ENN) | Value(T) | Value(P) |
| Mexican Stock Exchange | 30 | 30 | -9.0370 | 0.000 |
Comparisons were made with the paper called: “Optimization of Ensemble Neural Networks with Type-2 Fuzzy Integration of Responses for the Dow Jones Time Series Prediction”, where the same data from the series of the Dow Jones were used and we obtained that recurrent neural networks are better for predicting data from this series since there is a no significant difference in the results are better the recurrent neural that with ensemble neural network.
Therefore, we use a significance of 90% and according to the results obtained we can say that there is significant improvement with the ensemble neural network, as is summarized in Table 17.
5 Conclusions
In this work the design, implementation, and optimization of ensemble recurrent neural network for the prediction time are presented.
The chosen algorithm for this optimization was the GA, with which a total of 30 different experiments were made.
Comparisons were made with previously carried out works, in this way it can be said that genetic algorithms are an optimization technique that gives good results for the forecast of the time series. The main contribution in this paper was the creation of the new model of recurrent neural networks presented in this document that has shown good results since they are effective for the prediction of time series.
A hierarchical GA was applied to optimize the architecture of the RNN, in terms of parameters (NM, NL NN), to find better architecture and the time series error. The integration of the network responses was done with a type-1 and T2FS, to obtain the prediction error of the proposed time series, such as Mackey Glass benchmark, Mexican Stock Exchange, Dow Jones, and Exchange Rate of US Dollar/Mexican Pesos time series.
Analyzing the results, we can say that the combination of these intelligent computing techniques generates excellent results for this type of problem since the recurrent neural networks analyze the data of time series, the Genetic algorithms perform optimization and they helped us find the best architecture of the RNN, as well as to obtain the best solution to the proposed problem.
As future work we plan to perform optimization of the recurrent neural network with another optimization method, and make comparisons of the type-1 and type-2 fuzzy systems. We will also consider other complex time series to test the ability of our method for predicting complex time series.

