











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1. Introduction
Clustering is a data mining algorithm whose goal is the grouping of objects. Objects that are similar to each other should belong to the same cluster, and objects that are different from each other should belong to different clusters. There are several clustering algorithms in the literature, for example, partitioning methods, hierarchical methods, density-based method, the neural network-based method and the grid method, graph theory-based method, fuzzy methods. The disadvantage of clustering algorithms is that the algorithms also expect a cluster number as input. The optimal number of clusters can often not be determined by the user, therefore, an algorithm is needed to help the user determine the cluster number. In this paper, we present a representation mode and its evaluation by which the algorithms themselves determine the optimal cluster number. The article is structured as follows: Section 2 contains a brief introduction of clustering algorithms and literature review. Section 3 contains the traditional clustering algorithms, section 4 includes a cluster validation index (Silhouette index). Section 5 contains the construction algorithms, which are the followings: Nearest Neighbor, Nearest Insertion, Cheapest Insertion, Arbitrary Insertion, Farthest Insertion, Greedy. Section 6 includes the improvement algorithms, such as Genetic algorithm, Tabu Search and Particle Swarm Optimization. After that our representation and evaluation is detailed. In section 8 test results are detailed. After that conclusion remarks are made.
2. Clustering
Clustering is a widely used technique for grouping of elements. If two elements are similar, then belong to the same cluster. If they are different, they belong to different clusters. Optimal clustering is a difficult task because there are many ways to group a dataset.
There are lots of types of clustering algorithms, for example (Xu & Wunsch, 2005):
- Partitioning methods: elements are divided into k groups. Each group contains at least one element. After an initial clustering, a re-partitioning follows. At this point, the individual points may be placed in other clusters. The process ends when the elements move slightly (clustering changes only slightly). For example K-Means, Partitioning Around Medoid (PAM)
- Hierarchical methods: clusters can be represented by a dendrogram. There are two main methods of hierarchical clustering: the divisive and the agglomerative methods. The agglomerative methods are Single linkage, complete linkage, group average linkage, median linkage, centroid linkage, Ward’s method etc. The divisive methods are divisive analysis (DIANA), monothetic analysis (MONA).
- Other clustering methods include the density-based method, the neural network-based method and the grid method, graph theory-based method, fuzzy methods.
Some publications have been published in recent years that using metaheuristic algorithms for clustering. The Fast Genetic K-means Clustering Algorithm (Lu et al.,2004) combines the K-Means algorithm and the Genetic Algorithm. The algorithm applies the mutation, selection and crossover techniques (based on the Genetic Algorithm) and also has a K-Means operator. The K-Means operator (one step of the classical K-means algorithm) is the following: the elements are re-partitioned based to the closest cluster centroid. Another clustering analysis with the Genetic Algorithm is introduced in paper (Hruschka & Ebecken, 2003), where also the classical genetic operators are used. The objective function is based on the Average Silhouette Width. The author of paper (Maulik & Bandyopadhyay, 2000) is also used the Genetic Algorithm for the clustering of a data object. The objective function is the minimization of the distance of the objects to their cluster centroids. Their fitness calculation is the following: clusters are formed according to the centers encoded in the chromosome, after the clustering, the cluster centers will be the mean points of the respective clusters. Over the years many crossover and mutation techniques are developed to the Clustering Genetic Algorithm, for example, the one-point mutation, biased one-point mutation, which change the value of a center randomly picked (Kudova, 2007). The K-means mutation, which performs several steps of the k-means algorithm. (Kudova, 2007). The cluster addition and cluster removal modify the number of clusters (adds one center chosen randomly from the data set and deletes one randomly chosen center). (Kudova, 2007) For the fitness function in paper (Kudova, 2007) also the Silhouette is used.
Over the years the Particle Swarm Optimization (PSO) is also applied to clustering data. (Li & Yang, 2009). The PSO is applied with Hierarchical Clustering method, called CPSO Algorithm. A hybrid K-Means PSO algorithm is applied in paper (Van der Merwe & Engelbrecht, 2003). In this case, the result of the K-Means algorithm is improved with the PSO algorithm. The objective function of the PSO algorithm is based on the sum of the average distance of the object to their cluster centroids. In paper (Chen & Ye, 2012) also the PSO algorithm is applied to the clustering of the dataset. In this paper the encoding is also presented, which is the following: the string of the particle contains the cluster centers (in the paper the x and y coordinates of the cluster centroids).
In the case of applying the Ant Colony Optimization (ACO) to clustering data objects, the objective function can be also the minimization of the distance between the cluster elements and the centroids. (Runkler, 2005) The representation of the solution can be a string, which elements are numbers. The numbers indicate the cluster-object assignment. If the string is for example 2,1,3,1, it means, that the first object belongs to cluster 2, the second object belongs to cluster 1, the third object belongs to cluster 3, and the fourth object belongs to cluster 1. (Shelokar et al., 2004)
In paper (Osman & Christofides, 1994) the objective function of the Simulated Annealing algorithm is the minimization of the sum of distances between the clusters. The Capacitated Clustering Problem (CCP) is also solved with the Simulated Annealing algorithm. In the case of CCP, each object has a weight, and each cluster has a given capacity which must not be exceeded by the total weight of objects in the cluster.
Cluster Analysis with K-Modes and K-Prototype Algorithms in presented in (Madhuri et al., 2014). The authors used Iris Data Set and Cholesterol Data Set for Incremental k-Means, Contact-Lens Data Set and Post-operative Data Set for Modified k-Modes, Blood Information Data Set and Weather Data Set for k-Prototypes .
Automatic clustering with Teaching Learning-Based Optimization (TLBO) is presented in paper (Murty, Naik et al., 2014). The efficiency of the TLBO is compared also with Particle Swarm Optimization (PSO), Differential Evolution (DE). The efficiency of the algorithms is compared with the following benchmark datasets: Iris Data, Wine Data, Breast Cancer Data, Glass Data and Vowel Data.
The purpose of cluster validation indices is to compare individual clusters with each other considering certain aspects. Several such indices have been published, but these indices are not suitable for data sets of any size, density, shape. The authors of (Murty, Murthy et al., 2014) have developed a validation index (Homogeneity Separateness) that is effective for clusters of any shape, size, and density. Some clustering problems and the algorithms that solve it are illustrated in Table 1.
Table 1 Some clustering problems and the algorithms that solve it.
| Article | Clustering algorithm | Problem |
|---|---|---|
| (Milano & Koumoutsakos, 2002) | Genetic Algorithm | cylinder drag optimization |
| (Doval et al., 1999) | Genetic Algorithm | software systems |
| (Scheunders, 1997) | Genetic Algorithm | color image quantization |
| (Cui et al., 2005) | Particle Swarm Optimization | document clustering |
| (Omran et al., 2006) | Particle Swarm Optimization | image segmentation |
| (Omran et al., 2004) | Particle Swarm Optimization | image classification |
| (Paoli et al., 2009) | Particle Swarm Optimization | hyperspectral images |
| (Kalyani & Swarup, 2011) | Particle Swarm Optimization | security assessment in power systems |
| (Chiu et al., 2009) | Particle Swarm Optimization | intelligent market segmentation system |
| (Yang et al., 2010) | Ant Colony Optimization | multipath routing protocol |
| (Gao et al., 2016) | Ant Colony Optimization | dynamic location routing problem |
| (Zhao et al., 2007) | Ant Colony Optimization | Image segmentation-based |
| (Chang, 1996) | Simulated Annealing | Chinese words |
| (França et al., 1999) | Tabu Search | capacitated clustering problem |
| (El Rhazi & Pierre at al., 2008) | Tabu Search | wireless sensor networks |
| (Kinney et al., 2007) | Tabu Search | unicost set covering problem |
| (Hoang et al., 2013) | Harmony Search | energy-efficient wireless sensor networks |
| (Forsati, 2008) | Harmony Search | web page clustering |
| (Hoang, 2010) | Harmony Search | wireless sensor networks |
| (Mahdavi & Abolhassani, 2009) | Harmony Search | document clustering |
3. Traditional clustering algorithms
In this section, the applied traditional clustering algorithms are presented based on the literature.
3.1. K-Means
This procedure belongs to a group of partitioning methods. First, the elements
are clustered and then the elements move from the initial clusters to improve
the quality of the clustering. The algorithm uses the SSE function. Here, the
number of clusters (

4. Hierarchical methods
These algorithms organize the clusters into a hierarchical data structure. There are two types of algorithms: bottom-up and top-down. At the bottom-up, each element is initially a cluster, and then each cluster is merged into a single cluster. The top-down procedure is just the opposite. Here at first, there is a single cluster that contains all the elements, and we continually divide the clusters. At the end of the procedure, each element means a separate cluster. The following hierarchical clustering is applied in this paper: (Murtagh, 1983; Olson, 1995)
Single Linkage: The distance of the two clusters is the distance between the nearest objects of the two clusters:
Complete Linkage: the distance of two clusters is the distance between the farthest objects of two clusters:
Average method: the distance of two clusters is the quotient of the sum of the distances between the objects of two clusters and the number of clusters:
Centroid method: the distance of two clusters will be the distance of the center of two clusters:
Ward method: merging the two clusters that cause the least-squares error increase:
5. Cluster validation index
Let
where,
a(i) is the average distance between
the object
i
and other objects in cluster
- If
- If
- If
With the silhouette method, we can measure the efficiency of the whole cluster
result. For each element,
The following conclusions can be made from the average silhouette:
- 0.5 or higher value: good clustering
- 0.25-0.5: the clustering method is good, but some object should be moved to another cluster
- Less than 0.25: Not good clustering
Thus, the higher the average silhouette, the better the clustering.
Therefore, the objective function of our improvement algorithms is the average silhouette value.
6. Tour-based construction clustering algorithm
Behind this approach is the shortest route path tour connects neighboring elements. The edge distance is usually small, it connects elements from the same cluster, but the length is large if the edge connects two distinct clusters. Testing the distance of the connecting edges of the optimal tour the edges with high lengths denote existence of the separate clusters.
The construction algorithms construct one possible solution. Running time is relatively low. These algorithms always take locally the best steps. Most of the time, the global optimum is not achieved by their exclusive usage. The construction algorithms are based on the Traveling Salesman Problem algorithms.
6.1. Nearest neighbor
The algorithm always selects the unselected object that is closest to the last selected object. The algorithm is fast and simple. Figure 2 illustrates the pseudo code of the Nearest Neighbor algorithm.

6.2. Nearest insertion
The algorithm belongs to the group of insertion heuristics. The algorithm always selects the unselected object that is closest to the "tour". The distance between the "tour" and an object is interpreted by the algorithm as the minimum distance between the objects in the tour. The pseudo code of the Nearest Insertion algorithm is illustrated in Figure 3.

6.3. Cheapest insertion
This algorithm also belongs to the group of insertion heuristics. The algorithm always selects the object with the least "insertion cost" into the “tour". Figure 4 illustrates the pseudo code of the Cheapest Insertion.

6.4. Arbitrary insertion
This algorithm also belongs to the group of Insertion Heuristics. The algorithm randomly selects the next object to be inserted into the "tour". Figure 5 presents the presudo code of the Arbitrary Insertion algorithm.

6.5. Farthest insertion
This algorithm also belongs to the Insertion Heuristics group. The object that is farthest from the other objects is selected by the algorithm. Figure 6 illustrates the pseudo code of the Farthest Insertion algorithm.

6.6. Greedy
Each object builds the order from "edges" (pairs of objects) so that it
always selects the shortest "edge" that has not yet been selected and
does not form

7. Tour improvement-based clustering algorithm
Behind this approach is also the fact, that the shortest route path tour connects neighboring elements. This method tries to improve an existing path by rearranging the order of the elements iteratively. Their running time can be high, and their exclusive usage does not lead to the global optimum in most of the cases.
7.1. Genetic algorithm
The algorithm models natural processes (evolution). The algorithm works with a population of solutions. The population consists of individuals. (Milano & Koumoutsakos, 2002) Individuals have fitness values. Usually, an individual with better fitness value is better against other individuals. The pseudo code of the Genetic Algorithm is presented in Figure 8.

The first step is the initialization of the population. This process is usually done with randomly generated individuals. Then the fitness values of the individuals are calculated. Then the next population is created in a cycle while the termination condition is not met. The termination condition may be to achieve a certain iteration number or runtime. The next population is created by moving certain individuals unchanged, which is called elitism. The other elements are created with crossover and mutation techniques. We have used the 2-opt (Wu et al., 2007) as mutation, and the Partially Matched Crossover (PMX) (Lazzerini & Marcelloni, 2000) (Starkweather et al., 1991), the Order Crossover (OX) (Starkweather et al., 1991), and the Cycle Crossover (CX) (Starkweather et al., 1991) as crossover operators.
7.2. Tabu search (TS)
The algorithm maintains a taboo list containing the results of the last few steps. In the process, we can only take the neighbor of the current solution that is not in the taboo list. The taboo list must be changed at each iteration. If you add a new item, you must delete the first item from the beginning if the list is already full. (Glover & Laguna, 1998) The pseudo code of the Tabu Search is illustrated in Figure 9.

7.3. Particle Swarm Optimization
It maintains a population of possible solutions. The particles move through the search space using a simple mathematical formula. Particle movement is determined by the best search space positions found (the best position of the particle and the best position on the particle - best of all).
The algorithms use the following formulas:
1. Particle velocity updating formula:
Current particle velocity updating:
where the following notations are used:
•
•
•
•

8. Representation of clustering task, its evaluation, objective function
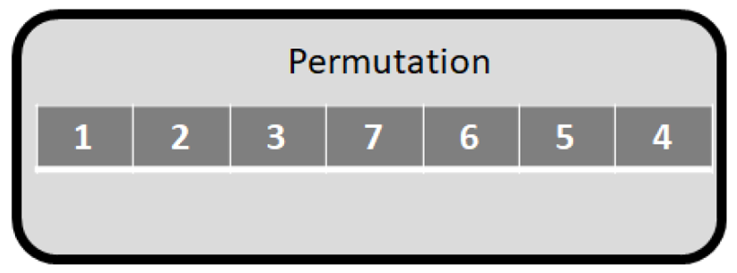
When applying construction and improvement algorithms for solving the clustering problem, we need to use a representation mode. In this paper permutation representation (mapping vector) is applied (Figure 11). The elements of the mapping vector are the individual objects. The objective function (of the improvement heuristics i.e., PSO, GA, TS) is to maximize the Silhouette value. The evaluation of the mapping vector is illustrated in Figure 12.

9. Test results
In this section, the test results are presented. First, test results for our own data then results for benchmark datasets are presented. The abbreviations and their meaning is presented in Table 2. Figure 13-17 illustrates the test result of the algorithms.
Table 2 The abbreviations and their meaning.
| Abbreviation | Meaning |
|---|---|
| KM | K-Means |
| SL | Hierarchical Clustering: Single Linkage |
| CL | Hierarchical Clustering: Complete Linkage |
| AM | Hierarchical Clustering: Average Method |
| CM | Hierarchical Clustering: Centroid Method |
| WM | Hierarchical Clustering: Ward Method |
| AI | Arbitrary Insertion |
| CI | Cheapest Insertion |
| FI | Farthest Insertion |
| G | Greedy |
| NI | Nearest Insertion |
| NN | Nearest Neighbour |
| PSO+R | Particle Swarm Optimization with randomly generated initial solutions |
| PSO+C,R | Particle Swarm Optimization with randomly and construction algorithms (AI, CI, FI, G, NN, NI) generated initial solutions |
| GA+R | Genetic Algorithm with randomly generated initial solutions |
| GA+C,R | Genetic Algorithm with randomly and construction algorithms (AI, CI, FI, G, NN, NI) generated initial solutions |
| TS+R | Tabu Search with randomly generated initial solution |
| TS+AI | Tabu Search with Arbitrary Insertion (AI) generated initial solution |
| TS+CI | Tabu Search with Cheapest Insertion (CI) generated initial solution |
| TS+FI | Tabu Search with Farthest Insertion (FI) generated initial solution |
| TS+G | Tabu Search with Greedy (G) generated initial solution |
| TS+NI | Tabu Search with Nearest Insertion (NI) generated initial solution |
| TS+NN | Tabu Search with Nearest Neighbour (NN) generated initial solution |
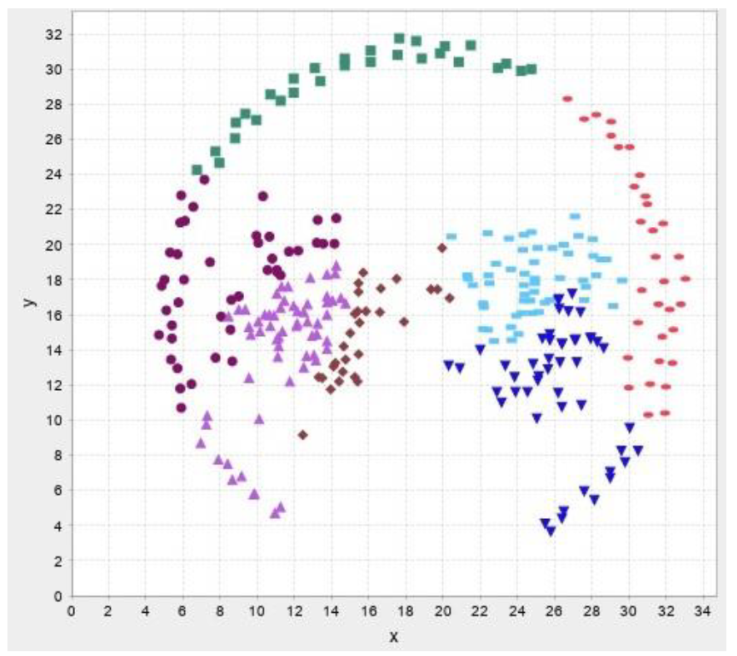
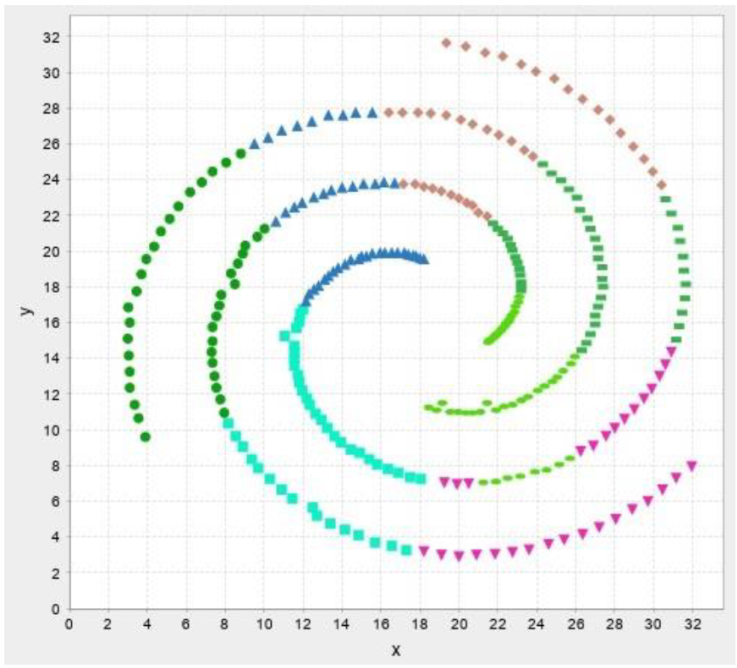
In Table 3-7 the N means the number of objects and k means the optimal number of clusters. In these tables the average values of 10 test runs are detailed. Table 8 present the summary of the test results.
Table 3 Test results for our data.
| Own data (N=100, k=10) | |||
|---|---|---|---|
| Method | Number of clusters | Silhoutte value | Running time (min) |
| KM | 6.0 | 0.8764 | 1.8126 E-5 |
| SL | 5.0 | 0.8470 | 2.7036 E-5 |
| CL | 5.0 | 0.8470 | 2.7898 E-5 |
| AM | 5.0 | 0.8470 | 2.7661 E-5 |
| CM | 5.0 | 0.8470 | 3.8139 E-5 |
| WM | 5.0 | 0.8470 | 3.8730 E-5 |
| AI | 5.5 | 0.8901 | 3.5881 E-6 |
| CI | 5.3 | 0.8863 | 3.4056 E-5 |
| FI | 5.8 | 0.8344 | 3.1482 E-4 |
| G | 5.0 | 0.9200 | 4.7099 E-5 |
| NI | 5.6 | 0.8152 | 2.9473 E-4 |
| NN | 5.0 | 0.9133 | 8.1065 E-6 |
| PSO+R | 1.0 | - | 0.0956 |
| PSO+C,R | 5.9 | 0.93055 | 0.09122 |
| GA+R | 1.0 | - | 0.0111 |
| GA+C,R | 1.0 | - | 0.0158 |
| TS+R | 1.0 | - | 0.1364 |
| TS+AI | 1.0 | - | 0.1342 |
| TS+CI | 1.0 | - | 0.1313 |
| TS+FI | 1.0 | - | 0.1352 |
| TS+G | 1.0 | - | 0.1233 |
| TS+NI | 5.3 | 0.7619 | 0.1352 |
| TS+NN | 1.0 | - | 0.1324 |
Table 4 Test results for Flame data.
| Flame (N=240, k=2) | |||
|---|---|---|---|
| Method | Number of clusters | Silhoutte value | Running time (min) |
| KM | 4.0 | 0.6275 | 2.4643 E-4 |
| SL | 3.0 | 0.3866 | 0.0010 |
| CL | 4.0 | 0.5545 | 8.8634 E-4 |
| AM | 5.0 | 0.5125 | 0.0010 |
| CM | 4.0 | 0.4754 | 0.0010 |
| WM | 4.0 | 0.5201 | 0.0010 |
| AI | 5.0 | 0.5662 | 1.0601 E-4 |
| CI | 5.2 | 0.4964 | 6.3844 E-4 |
| FI | 5.0 | 0.4397 | 0.0093 |
| G | 5.0 | 0.5192 | 0.0013 |
| NI | 5.0 | 0.4793 | 0.0094 |
| NN | 5.1 | 0.5155 | 2.1485 E-4 |
| PSO+R | 3.0 | 0.4377 | 13.1455 |
| PSO+C,R | 3.0 | 0.5388 | 13.7894 |
| GA+R | 3.0 | 0.5287 | 14.7877 |
| GA+C,R | 3.0 | 0.4012 | 12.1245 |
| TS+R | 3.2 | 0.5723 | 13.4832 |
| TS+AI | 3.1 | 0.5955 | 12.9809 |
| TS+CI | 3.0 | 0.4020 | 13.7845 |
| TS+FI | 3.0 | 0.5807 | 14.2906 |
| TS+G | 3.0 | 0.5292 | 12.8740 |
| TS+NI | 3.0 | 0.5237 | 13.1240 |
| TS+NN | 3.0 | 0.5070 | 14.1859 |
Table 5 Test results for Jain data.
| Jain (N=373, k=2) | |||
|---|---|---|---|
| Method | Number of clusters | Silhoutte value | Running time (min) |
| KM | 5.0 | 0.6530 | 9.8182 E-5 |
| SL | 6.0 | 0.6892 | 0.0013 |
| CL | 6.0 | 0.7244 | 0.0011 |
| AM | 6.0 | 0.7314 | 0.0011 |
| CM | 6.0 | 0.7313 | 0.0018 |
| WM | 6.0 | 0.7235 | 0.0019 |
| AI | 7.0 | 0.7279 | 2.8611 E-5 |
| CI | 7.2 | 0.6703 | 0.0015 |
| FI | 7.0 | 0.6295 | 0.0550 |
| G | 6.0 | 0.7294 | 0.0018 |
| NI | 6.6 | 0.6726 | 0.0503 |
| NN | 7.0 | 0.6846 | 2.4654 E-4 |
| PSO+R | 7.0 | 0.6026 | 21.0572 |
| PSO+C,R | 7.1 | 0.7367 | 22.7064 |
| GA+R | 7.2 | 0.6980 | 20.4734 |
| GA+C,R | 7.0 | 0.6777 | 21.9766 |
| TS+R | 7.0 | 0.6347 | 21.2806 |
| TS+AI | 7.0 | 0.6724 | 22.5610 |
| TS+CI | 7.0 | 0.7990 | 21.7342 |
| TS+FI | 7.0 | 0.7335 | 20.5112 |
| TS+G | 7.0 | 0.6438 | 20.4698 |
| TS+NI | 7.0 | 0.7059 | 21.2041 |
| TS+NN | 7.0 | 0.7266 | 21.6740 |
Table 6 Test results for Pathbased data.
| Pathbased (N=300, k=3) | |||
|---|---|---|---|
| Method | Number of clusters | Silhoutte value | Running time (min) |
| KM | 5.0 | 0.5676 | 4.5017 E-5 |
| SL | 5.0 | 0.4952 | 6.1105 E-4 |
| CL | 5.0 | 0.6247 | 6.0886 E-4 |
| AM | 6.0 | 0.5743 | 5.976 E-4 |
| CM | 6.0 | 0.6191 | 9.4529 E-4 |
| WM | 6.0 | 0.6360 | 0.0010 |
| AI | 6.4 | 0.6135 | 1.4689 E-5 |
| CI | 7.1 | 0.5564 | 7.6838 E-4 |
| FI | 6.1 | 0.5478 | 0.0231 |
| G | 8.0 | 0.6627 | 9.6926 E-4 |
| NI | 6.8 | 0.5479 | 0.0216 |
| NN | 6.8 | 0.5840 | 1.3669 E-4 |
| PSO+R | 6.5 | 0.6124 | 19.7260 |
| PSO+C,R | 6.8 | 0.4605 | 18.0736 |
| GA+R | 5.9 | 0.5030 | 19.0785 |
| GA+C,R | 5.7 | 0.5846 | 20.7408 |
| TS+R | 6.2 | 0.4322 | 19.4064 |
| TS+AI | 6.3 | 0.5785 | 19.3890 |
| TS+CI | 5.9 | 0.4850 | 19.3867 |
| TS+FI | 5.7 | 0.4553 | 19.8644 |
| TS+G | 6.4 | 0.5654 | 20.5816 |
| TS+NI | 6.5 | 0.5559 | 20.3076 |
| TS+NN | 6.0 | 0.5717 | 20.6610 |
Table 7 Test results for Spiral data.
| Spiral (N=312, k=3) | |||
|---|---|---|---|
| Method | Number of clusters | Silhoutte value | Running time (min) |
| KM | 6.0 | 0.5431 | 4.9849 E-5 |
| SL | 8.0 | 0.4710 | 7.4046 E-4 |
| CL | 7.0 | 0.5133 | 7.4932 E-4 |
| AM | 6.0 | 0.5448 | 0.0010 |
| CM | 6.0 | 0.5330 | 0.0010 |
| WM | 6.0 | 0.5448 | 0.0010 |
| AI | 7.4 | 0.6022 | 1.6550 E-5 |
| CI | 9.3 | 0.5499 | 8.5700 E-4 |
| FI | 8.1 | 0.5270 | 0.0271 |
| G | 10.0 | 0.5498 | 0.0010 |
| NI | 9.1 | 0.4985 | 0.0247 |
| NN | 9.6 | 0.5738 | 1.4543 E-4 |
| PSO+R | 8.2 | 0.5468 | 20.6559 |
| PSO+C,R | 8.5 | 0.4828 | 21.4954 |
| GA+R | 9.1 | 0.6571 | 20.0329 |
| GA+C,R | 8.4 | 0.8893 | 20.2922 |
| TS+R | 8.0 | 0.8092 | 21.0241 |
| TS+AI | 8.4 | 0.6826 | 20.5617 |
| TS+CI | 8.4 | 0.5627 | 20.8311 |
| TS+FI | 8.5 | 0.6349 | 20.1871 |
| TS+G | 7.9 | 0.6809 | 21.9084 |
| TS+NI | 8.2 | 0.6366 | 20.0576 |
| TS+NN | 8.3 | 0.5030 | 20.6369 |
Table 8 Summary.
| Summary | ||
|---|---|---|
| Method | Silhoutte value | Running time |
| KM | + | + |
| SL | + | + |
| CL | + | + |
| AM | + | + |
| CM | + | + |
| WM | + | + |
| AI | + | + |
| CI | + | + |
| FI | + | + |
| G | + | + |
| NI | + | + |
| NN | + | + |
| PSO+R | + | - |
| PSO+C,R | + | - |
| GA+R | + | - |
| GA+C,R | + | - |
| TS+R | + | - |
| TS+AI | + | - |
| TS+CI | + | - |
| TS+FI | + | - |
| TS+G | + | - |
| TS+NI | + | - |
| TS+NN | + | - |
In the following test results of the benchmark datasets from (Fränti & Sieranoja, 2014) is presented.
The test results show that despite the failure to reach the desired number of clusters, the silhouette values are high, so the implemented algorithms cluster relatively well. We do not recommend using improvement algorithms due to their high running time, we only recommend modified versions of construction algorithms and traditional clustering procedures.
10. Conclusion
In this article different tour-based clustering algorithms are compared with the classical methods and analyzed. After the literature review the traditional clustering algorithms (K-Means, Hierarchical Methods) are presented, then the Silhouette index to measure the quality of the clustering result. After that construction algorithms and improvement algorithms are detailed. Then our cluster representation technique and evaluation is described. After that test results are presented. In the test we have implemented and analyzed the main clustering methods and the tour construction and tour improvement methods. The comparison test performed on self-generated dataset and several clustering benchmark test: Flame, Jain, Pathbased and Spiral. Based on the test results the traditional clustering algorithms and the construction algorithms have efficiency in partitioning datasets with our representation and evaluation technique.





