











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1 Introduction
The detection of errors in the deployment processes either at the level of API's development, software using machine learning significantly reduces the implementation costs of these new requirements because their deployment dates would be prolonged by not being able to detect these errors in time.
Machine learning is evolving over the years in the IT area, companies are successfully implementing its use in business processes that involve return on investment in the short term, it is currently used to detect errors in systems before they happen, its method of action is proactive and not reactive because it is based on concrete facts and depending on it makes an internal analysis and determines the best way forward, this guided not only by Artificial Intelligence but also by a analyst who validates the proper functioning of the implemented.
To use machine learning it is first necessary to define whether it will be supervised or unsupervised [10, 5], once the type of machine learning to be used has been identified, it can be validated if a framework can be used or the development can be created from scratch, also the best known machine learning algorithms can be used such as linear regression [79], logistic regression [46, 57], decision tree [22, 23] among others, in order to meet the needs of what is presented.
The main objective of this study is to identify the state of the art of machine learning and its impact on API/software deployment processes and early error detection.
The paper is organized as follows. Section II presents the Background and related works, Section III details the Review Method, Section IV presents the Results and Discussion.
Finally, Section V presents the Conclusions and Future Research.
2 Background and Related Work
The advancement of new developments deployments, Internet of Things, big data and mobile computing with new technologies leads to the need for intelligent services that enable context awareness and adaptability to their changing contexts [97], offering products and services as in today's business world, providing reliable customer service is as important as offering better products to maintain a sustainable business model [87].
Data is the foundation of today's technologies and researchers, especially in machine learning and deep learning [92] require greater detail of the data. Security in data processing must give confidence to users so that they can interact with the various applications coming out of the emerging technology market, as well as machine learning [94] can detect anomalous user activities by analyzing sequences of user session data [89]. In financial institutions the problem in detecting online credit card fraud in e-commerce systems.
It has always been a concern that poses a major challenge for financial institutions and online merchants regarding financial losses [88], before these problems arise various solutions including the power to implement machine learning in their processes that have more risk to mitigate and reduce these threats in a short time, having real time information helps to identify in less time the existing threat, this in turn leads to the customization of products, services, provided to customers, to meet their needs, this has become a strategy to increase the added value of companies.
This study identifies a process within an organization that is deficient and how machine learning can help improve that process.
In this systematic review, information was collected to show the implications of the implementation of machine learning in organizations, as an improvement, in turn prevents possible errors by detecting them in time, depending on the configuration you have.
Likewise this review aims to provide the first literature review on the deployment of API's/software, error detection using Machine Learning, therefore to address the gap in the literature were used RQ's (Research Questions) on NER (named entity recognition) as people, organizations, locations, expressions of time and quantities that are most frequently presented in the abstracts, discussions and conclusions of the research, likewise it is considered important to mention that there are papers whose abstracts, discussions and conclusions are characterized by their high objectivity and low polarity on Machine Learning in the deployment of API's, software, error detection.
The research has been supported by technological tools such as Mendeley bibliographic manager and the Artificial Intelligence (RAj) technological tool authored by Dr. Javier Gamboa Cruzado, which was used to process the collected data.
3 Review Method
The present research was conducted by adopting the systematic review approach defined by Kitchenham [86], where the literature is collected and analyzed.
According to the study guidelines, it consists of 3 main phases: planning, conducting and documenting the review. The phases are shown in Figure 1 below.
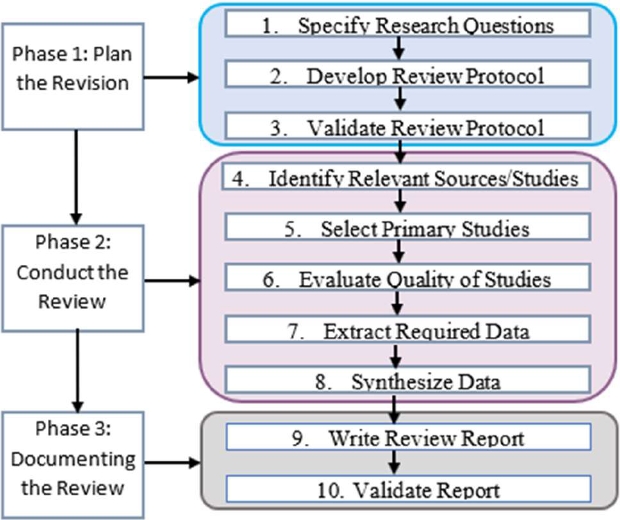
3.1 Research Problems and Objectives
In conducting a systematic literature review, the research questions assist in the search, extraction and analysis of data, as shown in Table 1 below.
Table 1 Research Questions and Objectives
| Research Question | Objetive |
| RQ1: What are the most widely used algorithms in Machine Learning research? | Determine the most commonly used algorithms in Machine Learning research. |
| RQ2: What are the Cooccurring Keywords in Machine Learning Research and their Impact on API Deployment? | Identify and select the keywords that present Cooccurrence in Machine Learning research and their impact on API Deployment. |
| RQ3: Which are the publications with the highest Objectivity in their Abstracts, by country, on Machine Learning and its impact on the Deployment of API's? | To know the publications that present a greater Objectivity in their Abstracts, by country, on Machine Learning and its impact on the Deployment of API's. |
| RQ4: Which types of Machine Learning are most commonly used in experimental research? | Identify which types of Machine Learning are most commonly used in experimental research. |
| RQ5: What are the named entities (NERs): people, organizations, places, time expressions and quantities that are most frequently presented in Machine Learning Research Abstracts and their impact on API Deployment? | Determine the named entities (NERs): people, organizations, places, time expressions, and quantities that occur most frequently in Machine Learning Research Abstracts and their impact on API Deployment. |
| RQ6: What are the most used and relevant Machine Learning keywords and their impact on API Deployment? | Identify the most used and relevant Machine Learning keywords and their impact on API Deployment. |
3.2 Information Sources and Search Strategies
The libraries that were used to search for the required research papers are: Scopus, Web of Science, IEEE Xplore, ACM Digital Library, ProQuest, ScienceDirect, Taylor & Francis Online, and Wiley Online Library. The search strategy included searching for keywords relevant to the study (see Table 2).
Table 2 Search Descriptors and their Synonyms
| Descriptor | Description |
| Machine learning | Independent Variable |
| Artificial intelligence | |
| Deep learning | |
| API Development | Dependent Variable |
| Deployment |
The search procedure was carried out using search equations for the study, as shown in Table 3.
Table 3 Information sources and search equation
| Source | Search equation |
| Scopus | (ALL ( ( "machine learning" OR "artificial intelligence" OR "deep learning" ) ) AND ALL ( ( "Api development" OR deployment ) ) ) |
| Web of Science | ("machine learning" OR "artificial intelligence" OR "deep learning") (All Fields) AND ("Api development" OR deployment) (All Fields) |
| IEEE Xplore | ("All Metadata":"machine learning" OR "All Metadata":"artificial intelligence" OR "All Metadata":"deep learning") AND ("All Metadata":"Api development" OR "All Metadata":deployment) |
| ACM Digital Library | [[All: "machine learning"] OR [All: "artificial intelligence"] OR [All: "deep learning"]] AND [[All: "api development"] OR [All: deployment]] |
| ProQuest | ("machine learning" OR "artificial intelligence" OR "deep learning") AND ("Api development" OR deployment) |
| ScienceDirect | ("machine learning" OR "artificial intelligence") AND ("Api development" OR deployment) |
| Taylor & Francis Online | [[All: "machine learning"] OR [All: "artificial intelligence"] OR [All: "deep learning"]] AND [[All: "api development"] OR [All: deployment]] |
| Wiley Online Library | "("machine learning" OR "artificial intelligence" OR "deep learning")" anywhere and "(“Api development” OR deployment)" anywhere |
3.3 Identified Studies
At the end of the search for papers, the quantities shown in Figure 2 are obtained.
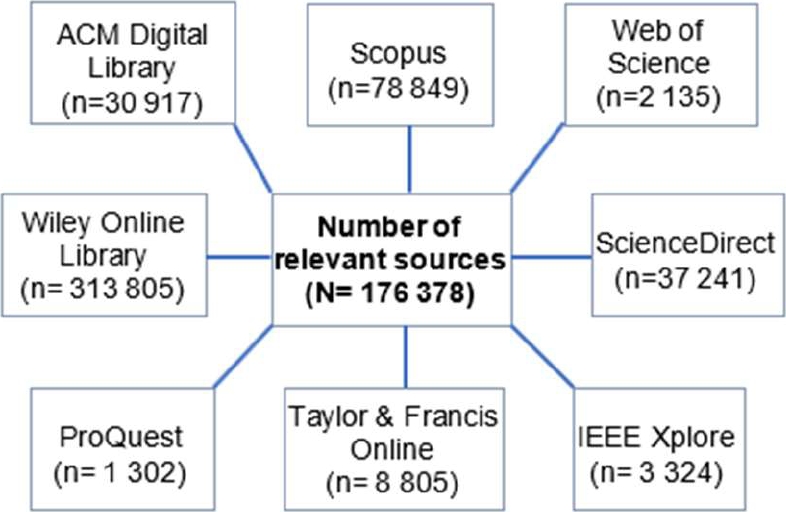
3.4 Exclusion Criteria
The Exclusion Criteria (EC) have been defined to accurately assess the quality of the literature. The papers that were formulated and used are:
EC1: The papers are older than 5 years.
EC2: The papers are not written in English.
EC3: The keywords of the papers are not very appropriate.
EC4: The papers were not published in journals or congresses.
EC5: The abstract of the papers is not very relevant.
EC6: The full text of the paper is not available.
EC7: The papers are repeated.
3.5 Study Selection
Originally 176378 papers were obtained based on the search performed using the keywords relevant to the study.
The selection and filtering steps used were as follows:
Step 1: Apply exclusion criteria to obtain only the most relevant ones.
Step 2: Apply quality assessment to include papers that give the best answers to the research questions posed.
The final result of applying the steps described above is 85 papers, as shown in Figure 3.

3.6 Quality Assessment
The quality rules helped to obtain a list of more specific results in the papers included for review. The quality criteria (QA's) that were formulated to evaluate the quality of the papers are:
QA1: Is the purpose of the research clearly explained?
QA2: Are the research findings detailed?
QA3: Is there a possibility to consult the researchers?
QA4: Is the research conducted in financial institutions?
QA5: Does the research detail unit tests? QA6: Was the research conducted during the pandemic?
QA7: Does the investigator have a postgraduate degree?
During this stage, the quality of the research submitted by the 85 studies that had met the exclusion criteria was assessed. The investigators jointly conducted an analysis of the papers and applied each of the criteria to assess the quality of the papers. The primary studies evaluated met each of the QA's.
3.7 Data Extraction Strategies
The final list of papers was used at this stage to extract the information needed to answer the set of research questions.
The information extracted from each paper included the following fields: paper ID and title, url, source, year, country, number of pages, authors, affiliation, number of citations, abstract, keywords, and sample size.
Not all the papers helped to answer all the research questions. Mendeley was used to perform the data extraction as shown in Figure 4.
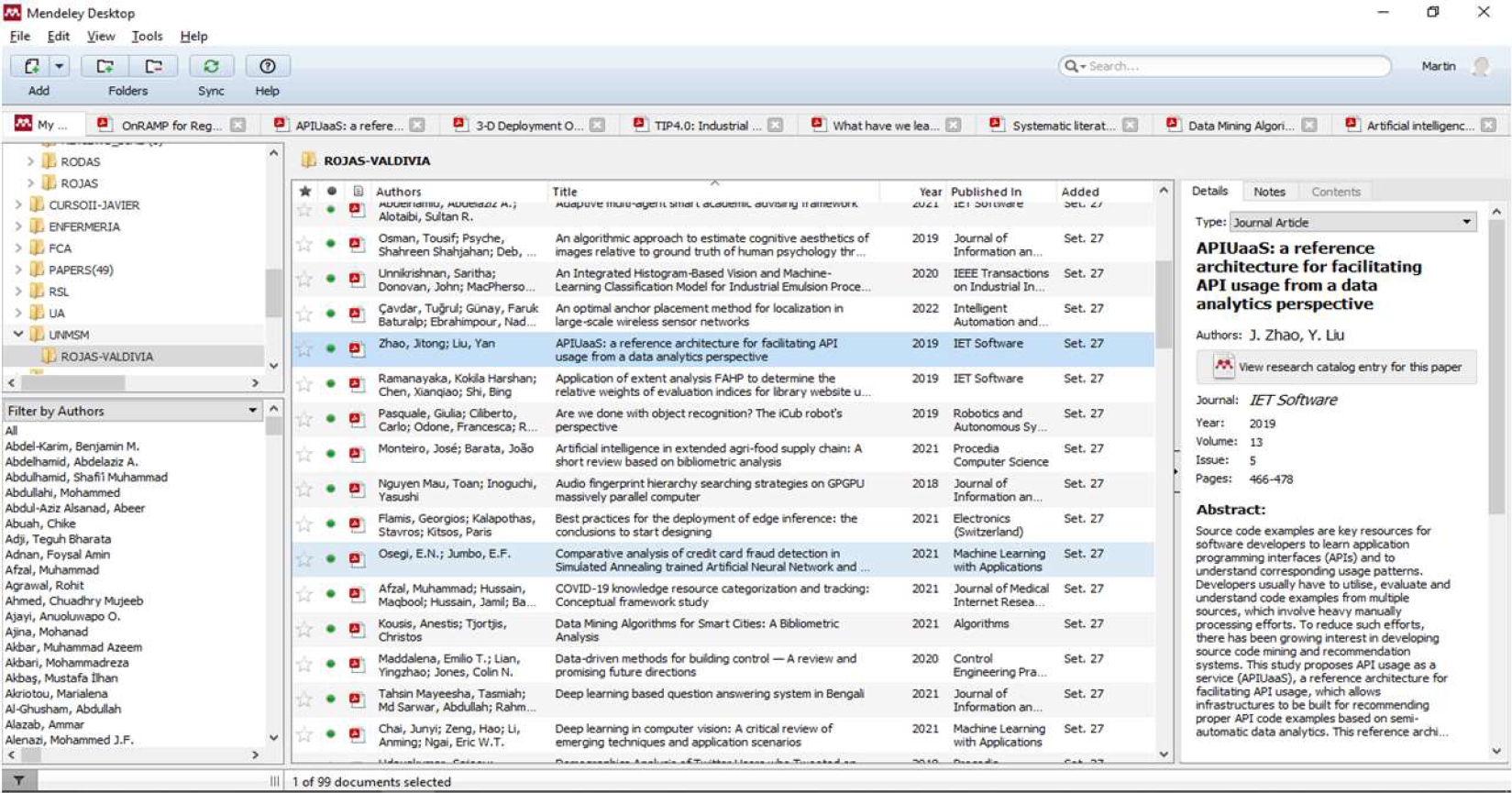
3.8 Synthesis of Findings
The information extracted for research questions RQ1-RQ6 are presented as qualitative and quantitative data to perform a descriptive and inferential statistical analysis to obtain the research answers; on the other hand, the development or analysis of the statistics obtained allowed the finding of certain research patterns occurred during the last 5 years (2017-2021).
4 Results and Discussion
In this section, it is expected to address the key findings obtained through the systematic review of the literature, as well as an interpretative discussion on these findings in the context of the impact of machine learning on the implementation of APIs. Here is a general breakdown of what could be included in this section:
4.1 General Description of the Studies
The paper selection process resulted in a total of 85 papers, these were selected for data extraction and analysis. Figure 5 shows the chronological distribution of published studies from 2017 to 2022.

The graph represents the evolution when applying Machine Learning for processes involving deployments in both productive and pre-productive environments independent of the organization and how this technology has been growing in the IT domain.
According to author Yildiz [91] the most profitable year for Machine Learning publications in the current field, especially with the internet of things and new technologies emerging, was 2018 with a total of 2071 publications.
According to the authors Chai et al. [92], the year that could be leveraged the most in terms of machine learning papers on application development scenarios was 2020.
As time and technology progresses each year has significantly increased the productivity of papers regarding Machine Learning.
Figure 6 shows that the United States contributed the most papers on Machine Learning with respect to the set of questions of the present research, US contributed 20 papers followed by China with 12 papers.
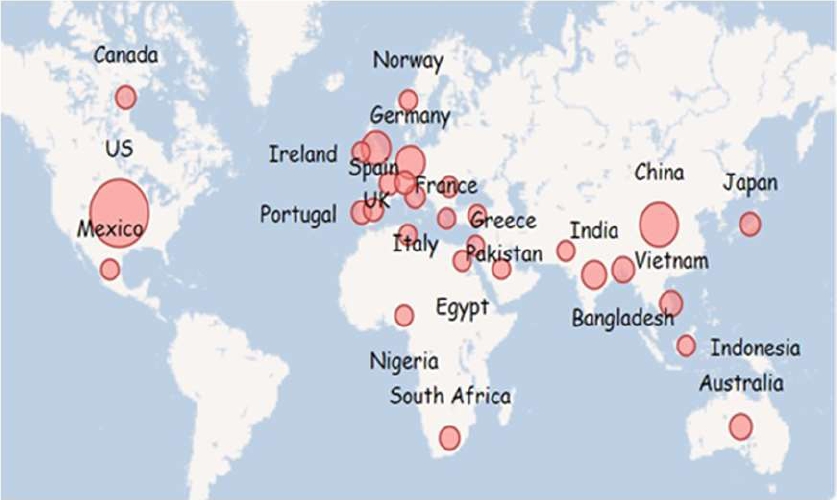
According to the authors Salod and Singh [93] identified the US as the country that has published the most on Machine Learning in prediction processes in the last 5 years with 803 papers, followed by China with 394, UK with 209, Canada with 169 and Germany with 147.
Likewise, the authors Akbari and Do [94] validate that the US is the country that has published the most on Machine Learning in the last decade on logistics process improvement, followed by Hong Kong, UK and Germany.
Figure 7 below shows the distribution of the sources that published the most papers on machine learning as a result of the search performed with the equations used.
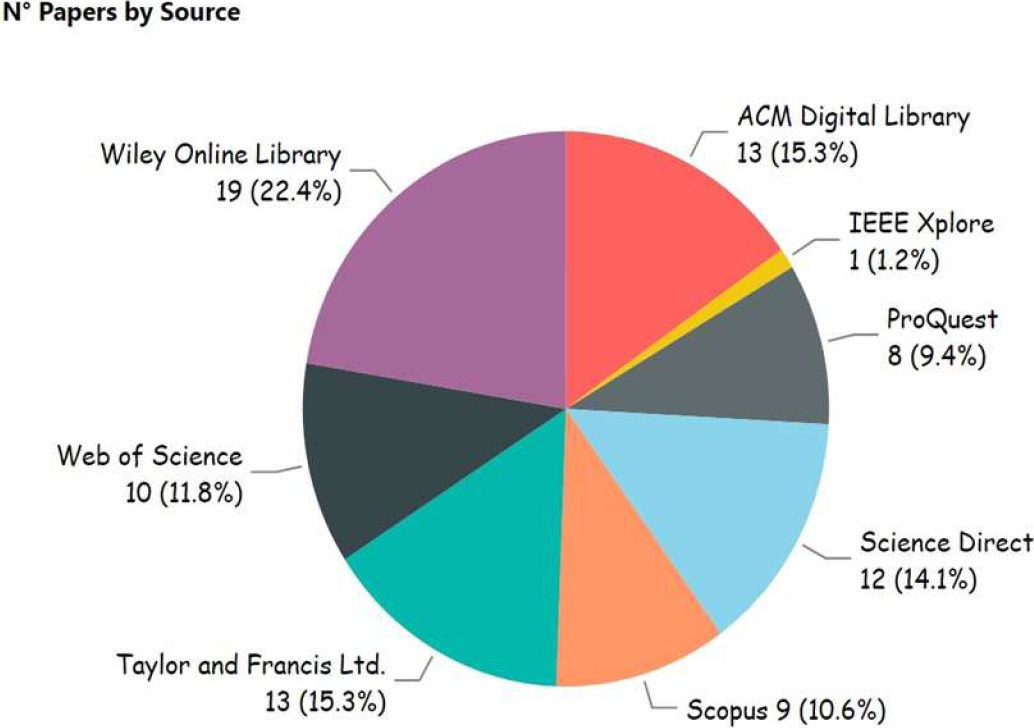
As can be seen, Wiley Online Library is the bibliographic source that has made the greatest contribution to this research with 22.4% of the papers, followed by ACM Digital Library with 15.3%, Taylor and Francis Online with 15.3%, Scienci Direct with 14.1%, Web of Science with 11.8%, Scopus with 10.6%, Proquest with 9.4% and finally IEEE Xplore with 1.1% of the papers, respectively.
The authors Nair et al. [95] consider Scopus as one of the largest databases for searching papers as they have papers whose publishers are internationally renowned.
Likewise, the authors Huang et al [96] use Web of Science as a bibliometric source; they consider this source for its quality of published papers because it helped them in their research.
Table 4 shows the number of papers by publication name (Journal or Congress) and by year in ascending order, detailing the number of research papers on Machine Learning from 2017 to 2022.
Table 4 Number of papers per publication and year
| Name of Publication | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 | Total |
| IET Software | 3 | 6 | 3 | 7 | 19 | ||
| Journal of Information and Telecommunication | 2 | 4 | 1 | 6 | 13 | ||
| Proceedings of the ACM on Programming Languages | 3 | 5 | 5 | 13 | |||
| Machine Learning with Applications | 12 | 12 | |||||
| IEEE Transactions on Industrial Informatics | 1 | 1 | 1 | 3 | |||
| Sensors | 3 | 3 | |||||
| Cybersecurity | 2 | 2 | |||||
| IEEE Transactions on Control of Network Systems | 1 | 1 | 2 | ||||
| Advanced Intelligent Systems | 1 | 1 | |||||
| Computer Speech and Language | 1 | 1 | |||||
| Control Engineering Practice | 1 | 1 | |||||
| Electronic Markets | 1 | 1 | |||||
| Electronics | 1 | 1 | |||||
| Eurasip Journal on Wireless Communications and N… | 1 | 1 | |||||
| Frontiers in Neuroscience | 1 | 1 | |||||
| IEEE Transactions on Automation Science and Engineering | 1 | 1 | |||||
| IEEE Transactions on Cybernetics | 1 | 1 | |||||
| … | … | ||||||
| Total | 1 | 6 | 14 | 18 | 44 | 2 | 85 |
IET Software leads with 19 papers, followed by Journal of Information and Telecommunication with 13 papers and Proceedings of the ACM on Programming Languages; Machine learning with Applications with 12 papers, IEEE Transactions on Control of Network Systems and Sensors with 3.
The authors Kousis and Tjortjis [97] mention that the publication media where Machine Learning publications were made, elaborated a ranking where IEEE Access leads followed by Sensors in second place, and Sustainable Cities and Society and Wiley Disciplinary Reviews are in the last positions.
Likewise, the authors [96] detail that the publication media that most helped their paper on Machine Learning in improving implementation in a pre-production environment was the International Journal of Production Research followed by Expert Systems with Applications.
4.2 Answers to the Research Questions
In this section, clear and well-founded answers to the posed research questions are provided. This segment is crucial for demonstrating how the carried-out research has addressed the proposed questions.
Principio del formulario.
According to the results of the literature review, Table 5 shows the most used algorithms on machine learning, highlighting Decision tree with 17 papers, followed by K-means with 16 papers, Logistic regression with 14 papers, Gradient Boosting with 10 papers. The other algorithms are also used but in a lower percentage.
Table 5 Most used algorithms using machine learning
| Algorithm | Reference |
Qty. (%) |
| Linear regression | [10] [23] [26] [29] [69] [70] | 6 (7.5) |
| Logistic regression | [2] [10] [22] [23] [24] [25] [26] [27] [29] [46] [57] [66] [70] [84] | 14 (17.5) |
| Decision tree | [1] [10] [22] [23][26] [28] [29] [30] [33] [36] [55] [66] [70] [78] [79] [80] [84] | 17 (21.25) |
| SVM | [7] [10] [79] | 3 (3.75) |
| Naive Bayes | [33] | 1 (1) |
| KNN | [79] | 1 (1) |
| K-means | [4] [11] [12] [22] [28] [29] [33] [36] [53] [66] [68] 77] [78] [79] [83] [84] | 16 (20) |
| Random forest | [27] | 1 (1) |
| Dimensionality reduction | [3] [24] [29] [30] [33] [36] [57] [75] [77] [84] [85] | 11 (13.75) |
| Gradient boosting | [10] [23] [26] [27] [28] [29] [30] [47] [69] [79] | 10 (12.5) |
According to the authors Udayakumar et al. [98], the algorithm that gave them the highest accuracy in their research results was the SVM with 86.80% and the least accurate was the Randon Forest.
RQ2: What are the Cooccurring Keywords in Machine Learning Research and their Impact on API Deployment?
According to the results of the literature review, the keywords such as "artificial intelligence", "machine learning", "internet of things" and "industry 4.0" are the ones that presented 3 concurrences each. (See Figure 8).

Keywords such as "artificial intelligence", "machine learning", "internet of things" and "industry 4.0" presented higher co-occurrences in the papers, but keywords such as "deep learning", "data mining", "finance", "digital financial", "systematic testing", "reiforcement learning" and "robotics" had 2 co-occurrences.
Authors Monteiro and Barata [99] detail that the keywords most commonly used to obtain papers on Machine Learning are: "artificial intelligence", "machine learning", "deep learning", and "neural networks".
RQ3: Which are the publications with the highest Objectivity in their Abstracts, by country, on Machine Learning and its impact on the Deployment of API's?
According to the results of the literature review, Figure 9 shows the United States (US) and China as the countries with the highest objectivity in the abstracts of their papers which shows that it is in line with their technological advancement over the other countries; this study was conducted between the year 2017 to 2022.
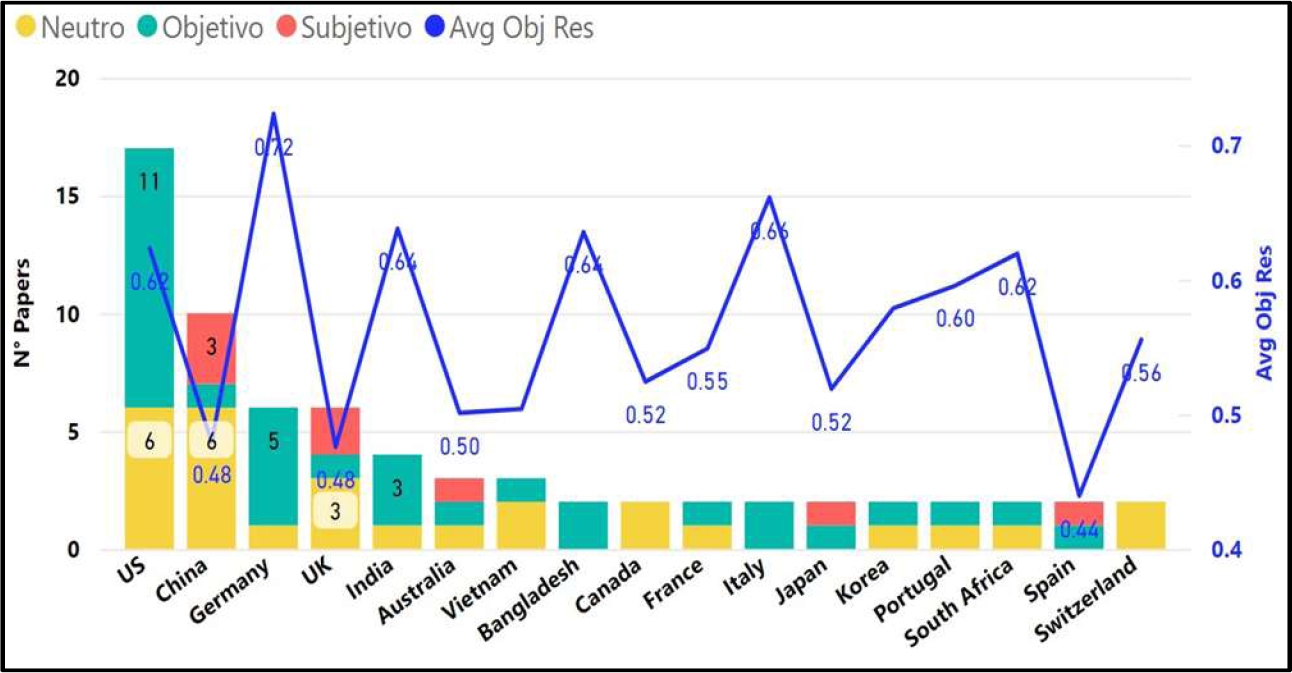
The authors Rejeb et al. [87] detail that the country that published the most on Machine Learning with respect to API, software, error detection deployments in the last 4 years was the US with 29% followed by China with 10% leaving Switzerland and Finland with a 2% share.
According to the results of the literature review, Table 6 shows the most used machine learning algorithms.
The most commonly used type of machine learning is Supervised Learning, according to Sharifi et al. [90] implemented in their paper on Signal Detection Robot with constrained computational resources.
RQ5: What are the Named Entities (NER): people, organizations, places, time expressions and quantities that are most frequently presented in Machine Learning Research Abstracts and their impact on API Deployment?
After performing a detailed analysis of the abstracts of the papers reviewed, using natural language processing (NLP) techniques, a series of NERs were obtained. The most frequent ones are shown in Figure 10.
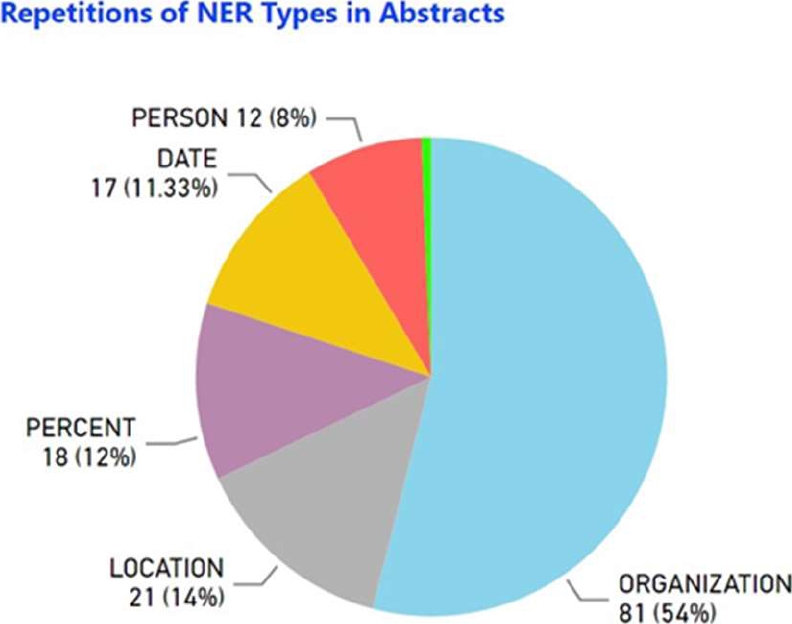
According to the results of the literature review, the Organization type NERs were found very frequently in the abstracts of the papers with 54%, the Location type with 21%, the Percentage type with 18%, the Date type with 11.3% and the Person type with 8% of the total percentage.
It is considered necessary to emphasize that the answer to this type of question cannot be compared with other papers since it is considered unique, this in order to be able to contribute to the research on Machine Learning so that it can be used as a reference in future papers.
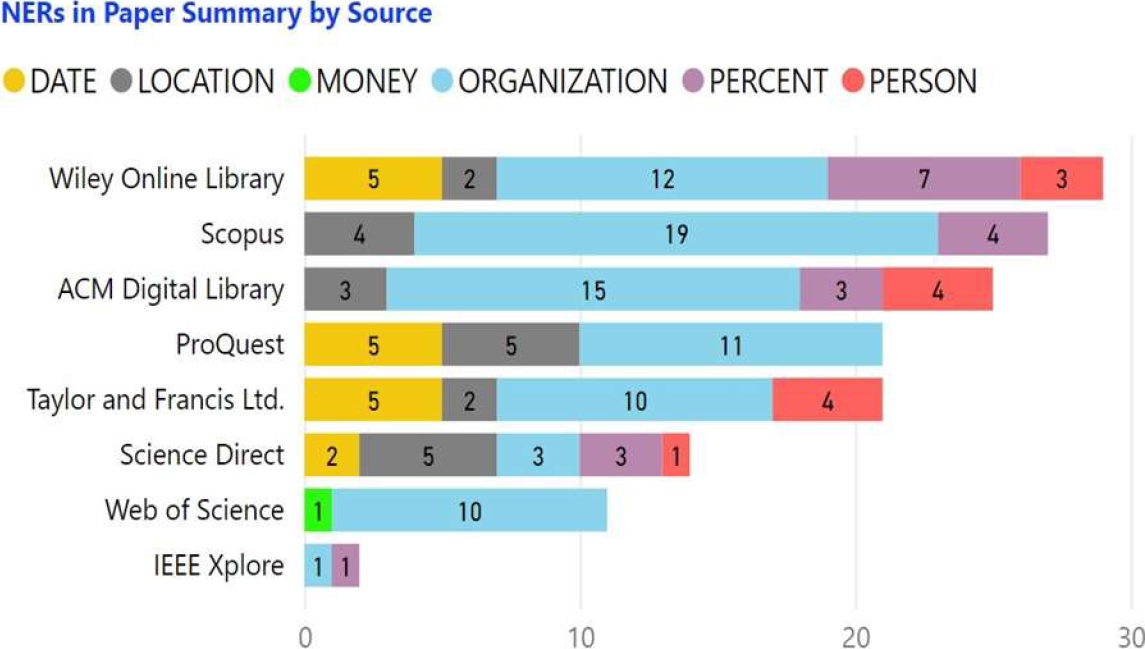
On the other hand, Figure 11 shows the NERs that were identified in the paper abstracts. They are shown ordered by bibliographic source, and the bibliographic source whose papers have the most NERs is Wiley Online Library, followed by Scopus. IEEE Xplore is the source with the fewest NERs in the abstracts of its publications.
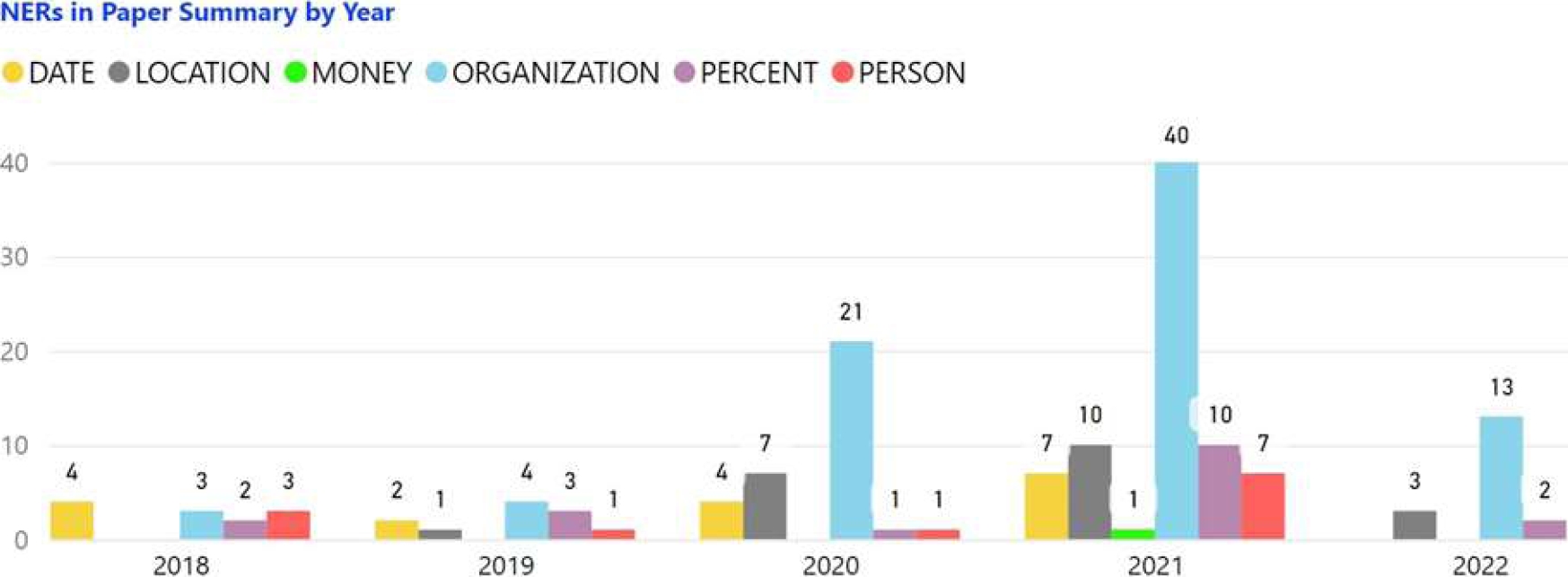
Finally, Figure 12 shows that in the years 2020 and 2021 the NERs of type Organization were presented more frequently in 21 and 40 abstracts of their papers respectively.
RQ6: What are the most used and relevant Machine Learning keywords and their impact on API Deployment?
According to the results of the literature review, Figure 13 shows the main keywords used in the research on machine learning solutions and their impact on API Deployment. To detail this, Figure 14 shows the number of keyword repetitions.

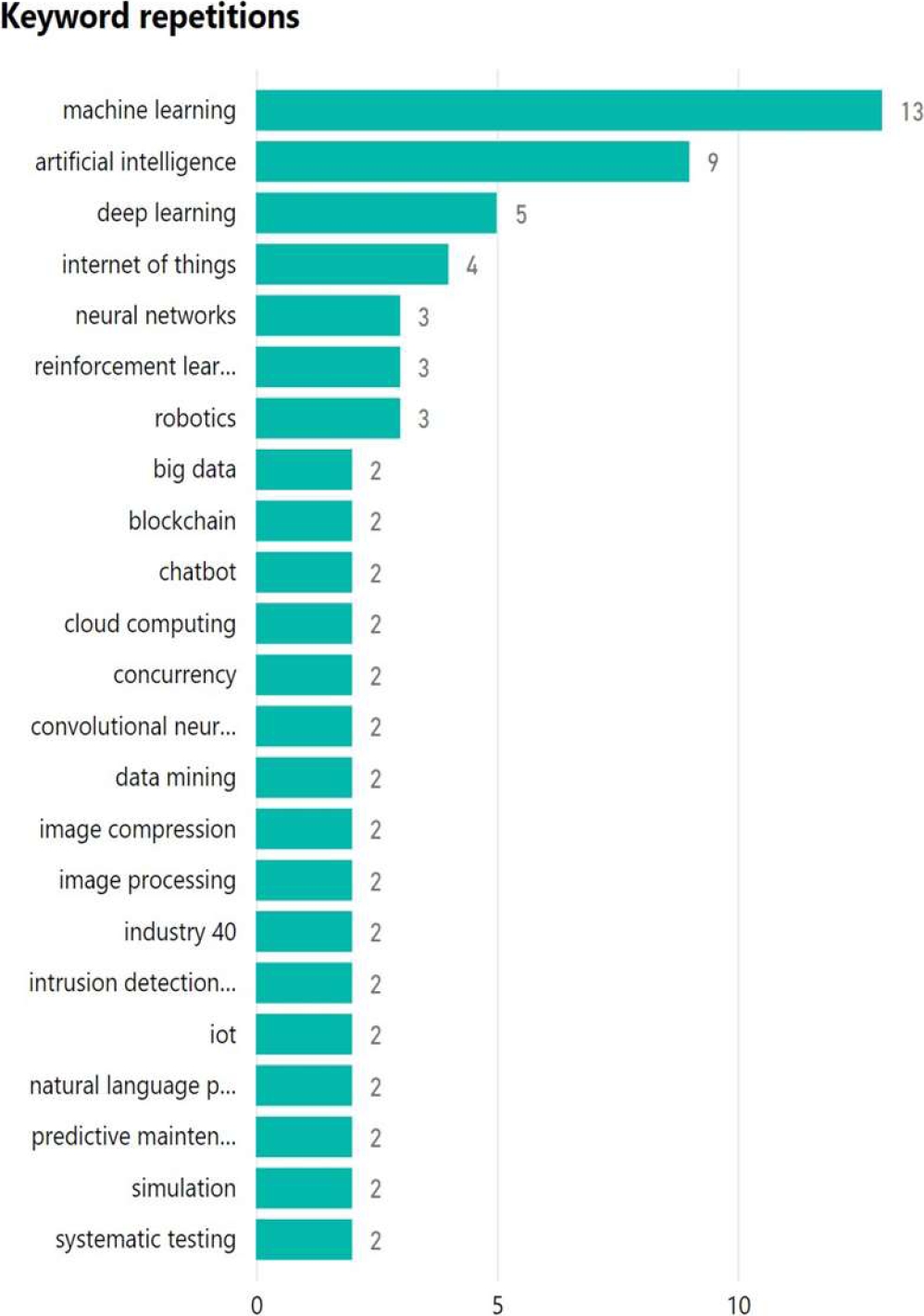
In the authors' paper Hasan et al. [100] include the keywords such as "machine learning", "big data analytics", "predictive analytics" among others.
Also [94] state that the most used keywords in their research were "machine learning", "artificial intelligence", "logistic", among others.
After the analysis of these 2 randomly selected systematic literature review papers, it is observed that the most repeated keyword is "machine learning" and "artificial intelligence" and it is found within the evaluation carried out.
5 Conclusions and Future Research
In conclusion, this study applies systematic literature review (SRL), which is an iterative process that combines the existing literature on a specific topic.
The objective was to address the issues by identifying, critically evaluating, and integrating the findings of all relevant individual high-quality studies that address one or more research questions.
This review has determined how far current studies on the use of machine learning have progressed in organizations that have successfully implemented it. It has also helped to formulate general statements, develop theoretical and practical implications, and make suggestions for future research.
We have answered, in detail, each of the RQs formulated, based on a thorough review of the 96 papers selected, discussed gaps and future directions. This review has some limitations that future research can address as it has a time limit for the papers that were reviewed from 2017 to 2021.
Therefore, future research should consider more recent publications to keep up with new technologies, methods, algorithms, and frameworks that may come out for machine learning in the future.

